- L’institut
- Activités
- L’IMI et vous
- Évènements
- Ressources
- Les Amis de l’IMI
- Contact
 FR
FR
Pendant près de 20 ans, des recherches financées par le gouvernement américain ont été effectuées sur les mécanismes du psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi. au Stanford Research Institute (SRI) ainsi qu’au Science Applications International Corporation (SAIC). Bien que la grande majorité des recherches effectuées sur le sujet soit classée secret-défense, la CIA a demandé à deux scientifiques d’évaluer les résultats obtenus lors de ces recherches après leur arrêt officiel en 1995. Nous vous proposons ici l’un de ces deux rapports : celui de Jessica Utts, staticienne et parapsychologueCe terme revêt de nos jours un double sens. Utilisé pour désigner les chercheurs de formation scientifique et universitaire qui étudient les phénomènes paranormaux dans le cadre de la parapsychologie scientifique, il renvoie aussi aux praticiens de l'occulte et du paranormal (voyants, médiums, magnétiseurs, etc.). On pourrait souhaiter que la première acception évoquée l'emporte dans le vocabulaire courant pour ainsi éviter toute confusion. L'ambiguïté du terme est volontiers entretenue par les critiques et détracteurs de la parapsychologie scientifique. Ceux-ci tentent ainsi, par un pernicieux effet d'amalgame maintenant une certaine confusion sémantique, de reléguer des recherches se voulant rationnelles sur ces questions en dehors du champ de la science. Des praticiens du paranormal peuvent avoir tendance, eux aussi, à entretenir cette ambiguïté. En se prétendant parapsychologues, ils espèrent sans doute, par la référence scientifique qu'ils s'attribuent, renforcer auprès de leurs clients l'image de professions en manque de reconnaissance sociale. De plus, le peu d'approfondissement que des enquêtes médiatiques trop souvent en mal de sensationnel consacrent à ce type de questions contribue à laisser perdurer la confusion, là où il faudrait au contraire faire preuve de discernement et de prudence. Que pouvons-nous dire des parapsychologues relevant du premier sens envisagé et que nous voudrions privilégier ici? D'origines universitaires variées, les chercheurs amenés à réfléchir aux questions parapsychologiques se recrutent aussi bien parmi des spécialistes des sciences dites humaines (psychologues, ethnologues, sociologues, etc.) que parmi des spécialistes des sciences dites exactes (mathématiciens, physiciens, biologistes, etc.). Des philosophes, des médecins et des ingénieurs se retrouvent également impliqués dans ce domaine de recherche. Seuls quelques laboratoires dans le monde emploient des chercheurs en parapsychologie à temps plein. Compte tenu du peu de place que l'institution scientifique accorde encore à la parapsychologie, la plupart des chercheurs n'y consacrent qu'une partie de leur temps, exerçant par ailleurs des fonctions en lien avec leur formation d'origine. Les premiers grands noms de la parapsychologie furent les pionniers de recherches qualifiées alors de psychiques , ou bien encore de métapsychiques. Parmi les plus connus, on pourrait citer le philosophe américain William James (1842-1910), tenant du pragmatisme, le physicien anglais William Crookes (1829-1919), rendu par ailleurs célèbre par la découverte du thallium, et le Français Charles Richet (1850-1935), prix Nobel de médecine en 1913. Deux psychologues américains ont ensuite particulièrement marqué l'histoire de la parapsychologie durant la seconde moitié du XXème siècle. Joseph Banks Rhine (1925-1980) est considéré comme le père de la parapsychologie quantitative car il a systématisé le traitement statistique des phénomènes paranormaux observés en laboratoire. Plus près de nous, Charles Honorton, en introduisant la technique du ganzfeld et en appliquant les techniques de méta-analyses aux données parapsychologiques, a permis de faire avancer le débat entre partisans et opposants de la parapsychologie. En France, c'est essentiellement autour de l'Institut métapsychique international, fondé en 1919, que se sont regroupés les principaux intellectuels interessés par ces questions. On citera, pour mémoire, les docteurs Gustave Geley (1865-1924) et Eugène Osty (1874-1938) ou bien encore les ingénieurs René Warcollier (1881-1962) et Henri Marcotte (1920-1987). Le spécialiste d'éthologie animale Rémy Chauvin, membre de l'Académie des sciences, est certainement, à l'heure actuelle, le scientifique le plus connu du grand public qui ait ouvertement déclaré son intérêt pour la parapsychologie, par le biais notamment d'expériences réalisées avec des animaux. Ce sont en fait de très nombreux chercheurs (qu'il faudrait certainement compter en milliers), issus de mondes scientifiques et intellectuels très divers, qui se sont passionnés pour la parapsychologie depuis plus d'un siècle, aussi bien en Europe qu'aux États-Unis, comme dans l'ex-URSS ou d'autres pays du monde. Dans son ouvrage "Somnambulisme et médiumnité" et plus particulièrement dans le tome II intitulé "Le Choc des sciences psychiques", le philosophe et sociologue Bertrand Meheust, reprenant l'histoire des débuts de la métapsychique, tente de comprendre les origines de l'incroyable entreprise d'occultation qui a pesé et qui pèse encore sur les travaux de plusieurs générations de parapsychologues. {Par Paul-Louis Rabeyron (extrait du dictionnaire des miracles et de l'extraordinaire chrétien, rédigé sous la direction de Patrick Sbalchiero, Fayard, 2000)} américaine, qui se propose de déterminer si oui ou non les phénomènes psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi. ont été prouvés et s’ils représentent un intérêt pour le gouvernement américain, en particulier dans le domaine du renseignement.
Nous examinerons tout d’abord, dans ce rapport, les recherches effectuées sur les phénomènes psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi. au cours des deux dernières décennies, afin de déterminer si leur existence est scientifiquement établie. Nous évaluerons ensuite si le psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi. peut s’avérer utile au gouvernement.
Le travail que nous étudierons en détail est une recherche qui fut commanditée par le gouvernement américain et qui fut effectuée au Stanford Research Institute (SRI), connu plus tard sous le nom de SRI international, ainsi qu’au Science Application International Corporation (SAIC).
Nous conclurons que l’existence des phénomènes psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi. est un fait établi si l’on se réfère aux normes utilisées dans les autres domaines scientifiques. Les résultats statistiques des recherches examinées sont bien au delà de ce que prévoit le hasard. L’argumentation selon laquelle ces résultats pourraient être dus à des biaisPrésence de patterns ou de défauts particuliers pouvant introduire une modification arbitraire des résultats et faussant ainsi leur validité (ex : un dé non équilibré ayant tendance à faire sortir souvent le même chiffre). méthodologiques sera également réfutée. Des effets similaires à ceux mis en évidence au sein du programme de recherche commandité par le gouvernement, au SRI et au SAIC, ont été reproduits dans de nombreux laboratoires à travers le monde. Une telle uniformité au niveau des résultats ne peut être expliquée en termes de biaisPrésence de patterns ou de défauts particuliers pouvant introduire une modification arbitraire des résultats et faussant ainsi leur validité (ex : un dé non équilibré ayant tendance à faire sortir souvent le même chiffre). ou de fraude.
La taille des effets psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi. semble se situer entre ce que les scientifiques travaillant dans le domaine des sciences sociales (social science) appellent un effet léger ou moyen. Cela signifie que ces effets sont suffisamment constants pour être reproduits lors d’expériences correctement réalisées, avec un nombre d’essais suffisant et sur une période suffisamment longue. Il est possible, dans ces conditions, d’obtenir des résultats statistiques démontrant la reproductibilitéPossibilité de reproduire des résultats identiques ou similaires dans des expérimentations de même type. du psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi..
D’autres paramètres ont été mis en évidence. Ils indiquent précisément la façon dont il est nécessaire de conduire des expériences et de mener des applications utilisant le psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi.. L’un de ces paramètres est, par exemple, qu’un agentDans les cas spontanés, la personne vivant lévénement dont le récepteur va recevoir linformation ; dans les expérimentations de télépathie, lémetteur ; dans la psychokinèse :le sujet, considéré comme source du psi. (sender) ne semble pas nécessaire. En outre, les recherches sur la précognitionLa précognition est la connaissance dun événement futur qui ne pourrait être ni prédit ni inféré par des moyens normaux., dans lesquelles les réponses ne sont connues qu’après l’expérience, ont également donné lieu à des résultats concluants. Les travaux récents suggèrent que s’il existe un sens psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi., il fonctionne de la même façon que nos cinq sens, en détectant des variations dans notre environnement. Les physiciens cherchent à l’heure actuelle à comprendre la nature du temps. Il se pourrait qu’il existe un sens psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi., balayant le futur à la recherche de variations repérables de la même façon que nos yeux « scannent » l’environnement à la recherche de changements visuels ou que nos oreilles réagissent à de brusques variations sonores.
Nous recommandons que les prochaines expériences soient orientées vers la compréhension des processus psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi. et sur la façon de les rendre utilisables. Il y a peu d’intérêt à continuer à mener des expériences en vue de prouver l’existence du psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi., puisqu’il est difficile d’apporter davantage d’éléments en ce sens, étant donné l’accumulation des données déjà existante à l’heure actuelle.
Le but de ce rapport est d’examiner l’ensemble des données rassemblées durant les dernières décennies, afin de de déterminer si des interactions psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi. sont possibles. Nous verrons également si le psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi. peut être utilisé efficacement par le gouvernement, et si les recherches effectuées jusqu’à maintenant fournissent une explication de la façon dont le psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi. fonctionne.
Il n’y a pas de raison d’aborder ce domaine différemment que n’importe quel autre champ d’investigation scientifique se fondant sur des méthodes statistiques. Toute discussion basée sur la croyance devrait être limitée aux éléments qui ne sont pas directement déductibles des données, notamment ceux qui concernent l’étude des problèmes méthodologiques pouvant avoir une influence sur les résultats. Nous remarquons trop souvent que certaines personnes s’opposent aux questionnements portant sur l’existence du psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi. en fonction de leurs croyances personnelles plutôt que par un examen attentif des données scientifiques.
Un des objectifs de ce rapport est de fournir une vue d’ensemble générale des données récentes obtenues en parapsychologieEtude rationnelle et pluridisciplinaire des faits semblant inexplicables dans l'état actuel de nos connaissances, et mettant en jeu directement le psychisme et son interaction avec l'environnement. C'est en 1889 que l'Allemand Max DESSOIR proposa les termes de parapsychologie pour "caractériser toute une région frontière encore inconnue qui sépare les états psychologiques habituels des états pathologiques", et de paraphysique pour désigner des phénomènes objectifs qui paraissent échapper aux lois de la physique classique. On parle plus spécifiquement de parapsychologie expérimentale pour désigner la parapsychologie dans le cadre du laboratoire. More. Nous présenterons également les outils scientifiques nécessaires pour que le lecteur consciencieux puisse tirer ses propres conclusions au vu des données disponibles. Ces outils consistent en un point de vue général sur la façon dont on évalue les données statistiques, et en une liste de problèmes méthodologiques spécifiques aux expériences parapsychologiques.
Les recherche sur le psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi. commanditées par le gouvernement américain remontent au début des années 70, lorsqu’un programme de recherche fut lancé au Stanford Research Institute, maintenant appelé SRI International. Ce programme continua d’exister jusqu’en 1989. L’année suivante, le soutien financier du gouvernement fut transféré à un autre programme, au Science Applications International Corporation (SAIC), sous la direction du Dr. Edwin May qui avait travaillé au sein du programme du SRI depuis le milieu des années 70. May a été également directeur de ce projet de recherche de 1986, et ce jusqu’à la fin du programme.
Ce rapport portera principalement sur les travaux les plus récents du SAIC. La section 2 décrit les problèmes statistiques et méthodologiques de base, nécessaires pour comprendre ce rapport ; La section 3 est une discussion à propos du programme du SRI ; la quatrième section porte sur le travail du SAIC (dont certains détails figurent en annexe) ; La section 5 concerne la validation externe des résultats par ceux obtenus par d’autres laboratoires ; La section 6 inclut une discussion sur l’utilité de ces facultés pour le gouvernement et la section 7 propose des conclusions ainsi que diverses recommandations.
2.1 Définitions et protocoles de recherche
Deux types de phénomènes sont généralement considérés comme relevant des « facultés psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi. ou paranormales ». Celles-ci sont classiquement appelées perceptions extra-sensoriellesConnaissance dun événement extérieur sans lintervention des sens connus, ou parfois comportement répondant à cet événement. On distingue la télépathie, la clairvoyance et la précognition. (PES – ESPPerception extrasensorielle ; connaissance d’un événement extérieur sans l’intervention des sens connus, ou parfois comportement répondant à cet événement. More en anglais), lorsque des informations sont obtenues par des moyens inexpliqués, et psychokinése, quand l’environnement physique est modifié selon des modalités qui demeurent inconnues.
Le laboratoire du SAIC emploie une terminologie plus neutre pour dénommer ces facultés ; il se réfère à l’ESPPerception extrasensorielle ; connaissance d’un événement extérieur sans l’intervention des sens connus, ou parfois comportement répondant à cet événement. More en tant que « connaissance anormale » (C.A. – A.C. en anglais) et fait mention de la psychokinèseCapacité à influencer mentalement un objet, un processus ou un système sans lutilisation de mécanismes ou dénergies connues. On distingue la bio-psychokinèse , la micro-psychokinèse et la macro-psychokinèse . en tant que perturbation anormale (P.A. – A.P. en anglais). La grande majorité des travaux effectués au SRI et au SAIC portaient sur la connaissance anormale. Cependant, quelques recherches ont également été effectuées sur la perturbation anormale.
La connaissance anormale est subdivisée en trois catégories qui sont dépendantes de la source manifeste de l’information obtenue. Ainsi, si l’information semble provenir d’une autre personne, ces facultés sont nommées télépathieLa télépathie désigne un échange dinformations entre deux personnes nimpliquant aucune interaction sensorielle ou énergétique connue. ; si elle semble venir en temps réel, mais non d’une autre personne, on la nomme clairvoyanceConnaissance d'objets ou d'événements à distance sans l'intermédiaire des sens. More ; et si l’information ne semble pouvoir avoir été obtenue que par la connaissance du futur, on utilise le terme de précognitionLa précognition est la connaissance dun événement futur qui ne pourrait être ni prédit ni inféré par des moyens normaux..
Il est possible de déterminer s’il s’agit de précognitionLa précognition est la connaissance dun événement futur qui ne pourrait être ni prédit ni inféré par des moyens normaux., en demandant à un sujet de décrire une cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). dont la nature ne sera déterminée qu’ultérieurement. Il est en revanche plus délicat d’éliminer la précognitionLa précognition est la connaissance dun événement futur qui ne pourrait être ni prédit ni inféré par des moyens normaux. lors d’expériences évaluant la télépathieLa télépathie désigne un échange dinformations entre deux personnes nimpliquant aucune interaction sensorielle ou énergétique connue. ou la clairvoyanceConnaissance d'objets ou d'événements à distance sans l'intermédiaire des sens. More, puisqu’il est pratiquement impossible d’être sûr que les sujets n’aient pas accès à la réponse correcte à un moment donné dans le futur. Ces distinctions sont importantes quand il s’agit de donner une explication à la connaissance anormale.
La grande majorité des expériences portant sur la connaissance anormale, au SRI et au SAIC, ont utilisé des techniques connues sous le nom de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More (remote viewingLe Remote Viewing (vision à distance) est une technique utilisée lors de protocoles de parapsychologie en vu d'étudier les perceptions extra-sensorielles. Les techniques de vision à distance ont pour origine les travaux de René Warcollier. Elle ont ensuite été développées au sein du programme de vision à distance commandité par la CIA dans les années 1970. Jusqu'en 1995, les chercheurs qui ont participé à ce programme se sont efforcés d'utiliser les techniques de remote viewing afin de tenter de développer des applications du psi, en particulier dans le domaine du renseignement.). Dans ces expériences, un sujet psiIndividu qui semble produire des phénomènes psi de façon particulièrement intense ou fiable. (viewer) essaye de dessiner ou de décrire (voire les deux) une « cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). » qui peut être une photographie, un objet ou une courte séquence vidéo. Tous les biaisPrésence de patterns ou de défauts particuliers pouvant introduire une modification arbitraire des résultats et faussant ainsi leur validité (ex : un dé non équilibré ayant tendance à faire sortir souvent le même chiffre). sensoriels connus et susceptibles de permettre de recevoir des informations sont supprimés. Le sujet psiIndividu qui semble produire des phénomènes psi de façon particulièrement intense ou fiable. est parfois aidé par un moniteur (monitor) qui lui pose des questions ; naturellement, dans ces cas-là, le moniteur ne connaît pas la réponse. Il arrive également qu’une autre personne, l’agentDans les cas spontanés, la personne vivant lévénement dont le récepteur va recevoir linformation ; dans les expérimentations de télépathie, lémetteur ; dans la psychokinèse :le sujet, considéré comme source du psi. (sender), regarde la cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). pendant la session.
Dans la plupart des cas, le sujet psiIndividu qui semble produire des phénomènes psi de façon particulièrement intense ou fiable. reçoit un feed-back à posteriori qui lui permet de prendre connaissance de la réponse exacte, rendant de ce fait difficile l’élimination d’une précognitionLa précognition est la connaissance dun événement futur qui ne pourrait être ni prédit ni inféré par des moyens normaux. comme explication des résultats positifs (qu’un agentDans les cas spontanés, la personne vivant lévénement dont le récepteur va recevoir linformation ; dans les expérimentations de télépathie, lémetteur ; dans la psychokinèse :le sujet, considéré comme source du psi. ait été présent ou non).
La plupart des expériences portant sur la connaissance anormale, aussi bien SRI qu’au SAIC, étaient du type « réponses libres« , dans lesquelles les sujets étaient simplement invités à décrire la cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.).. Une expérience à « choix forcé » est au contraire une expérience dans laquelle on présente un nombre restreint de choix parmi lesquels le sujet doit choisir. Il est certes plus facile d’évaluer statistiquement les expériences à choix forcé, mais elles sont généralement moins réussies que les expériences à réponses libres. Une partie du travail effectué au SAIC a eu pour objectif d’expliquer ce phénomène.
2.2 Problèmes statistiques et définitions
Peu de facultés humaines sont reproductibles à volonté. Par exemple, même les meilleurs batteurs des grandes ligues de base-ball ne peuvent frapper la balle exactement de la même façon à chaque lancé, et cela même si on leur demande. Nous ne pouvons pas non plus prévoir quand un joueur fera un home run. En fait, nous ne pouvons même pas déterminer à l’avance si il y aura un home run lors d’un match. Mais cela ne signifie pas pour autant que les home run n’existent pas.
La preuve scientifique dans le domaine statistique est basée sur la reproduction d’une même performance, ou d’une même relation sur le long terme. Nous ne nous attendons pas à ce qu’une pièce de monnaie tombe cinq fois sur pile et cinq fois sur face d’affilé au cours de dix lancers, mais nous pouvons prévoir que la proportion de pile et de face se situe à environ la moitié sur une très longue série de lancés. De même, un bon batteur de base-ball ne frappera pas la balle avec la même précision lors de chaque match, mais ses résultats seront relativement stables sur la durée.
Il devrait en être de même pour les phénomènes psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi.. Cependant même s’il existe réellement un effet de ce type, il se pourrait qu’il ne puisse jamais être reproduit sur commande et sur un nombre restreint d’essais, et cela même si nous en comprenions le fonctionnement. Cependant, sur la durée et dans le cadre d’expériences de laboratoire contrôlées, nous devrions constater un niveau homogène de résultats, supérieur à ce que prévoit le hasard.
Ainsi, de la même façon que le niveau de réussite prévu peut varier selon les différents joueurs et les différentes conditions au base-ball, des joueurs sélectionnés, aux capacités stables, testés dans les conditions identiques, devraient produire des résultats reproductibles sur la durée. Nous montrerons dans ce rapport qu’une telle reproduction, selon ce type de critères, a bien été atteinte pour la connaissance anormale.
2.2.1 P-values et comparaison avec le hasard
Dans n’importe quel domaine scientifique, les preuves fondées sur les statistiques proviennent de la comparaison entre les résultats obtenus avec ce que l’on pourrait obtenir par le simple fait du hasard.
Prenons l’exemple suivant pour illustrer ce principe : sans intervention spécifique, environ 51 % des naissances aux États-Unis correspondent à des naissances de garçons. Supposons que quelqu’un prétende avoir une méthode qui permette d’augmenter les chances d’avoir un bébé du sexe désiré. Nous pourrions étudier sa méthode en comparant combien de fois des garçons sont nés par rapport aux résultats prévus. Si ce pourcentage était plus grand que la probabilité de 51 % sur la durée, alors l’affirmation initiale serait soutenue sur le plan statistique.
Les statisticiens ont développé des méthodes pour comparer les résultats avec ce qui est prévu par le hasard. Ainsi, lors de l’étude des résultats d’une expérience, la p-value est la réponse à la question suivante : « Si le hasard était à l’origine des résultats, quel serait la probabilité d’observer des résultats aussi probants ou plus probants ? » Si la réponse à cette question donne une p-value très faible, alors la plupart des chercheurs sont d’accord pour éliminer le hasard comme cause probable. Il est ainsi communément admis de dire que si la p-value est de 5 % (0,05) ou moins, nous pouvons écarter le hasard comme cause probable d’explication. Dans de tels cas, les résultats sont dits statistiquement significatifs. Évidemment, plus la p-value est petite, plus l’effet du simple hasard semble improbable.
A noter que lorsque seul le hasard opère, il est cependant possible de trouver un résultat statistiquement significatif environ 5 % du temps. C’est notamment pour cette raison que les scientifiques requièrent la reproduction des résultats d’une expérience avant d’être convaincus que l’hypothèse du hasard puisse être écartée.
2.2.2 Reproduction et tailles d’effets
Au cours des dernières décennies, les scientifiques se sont rendus compte que pour reproduire convenablement des résultats expérimentaux, il était nécessaire de se concentrer sur la magnitude de l’effet, ou taille d’effet, plutôt que sur la reproduction de la p-value, car cette dernière dépendait fortement de la taille de l’étude. Dans une étude très grande, il faudra seulement une faible taille d’effet pour écarter l’hypothèse du hasard de façon convaincante. Dans une étude très petite, il faudra en revanche un effet très fort pour écarter l’hypothèse du hasard de façon probante.
Dans notre hypothétique expérience portant sur le pourcentage de garçons à la naissance, supposons que 70 naissances sur 100 conçues pour produire des garçons aient effectivement produit des garçons, au lieu des 51 % prévus par le hasard. L’expérience aurait une p-value de 0,0001, écartant ainsi d’une façon convaincante l’hypothèse du hasard. Supposons maintenant que quelqu’un essaye de reproduire cette expérience avec seulement dix naissances et trouve 7 garçons, soit également 70 %. Le nombre de naissances étant plus petit dans cette expérience, cette dernière aurait une p-value de 0,19 et ne serait donc pas statistiquement significative. Si nous devions simplement nous positionner concernant la réalité ou non de l’effet étudié, la conclusion serait donc qu’il s’agit d’un échec de la reproduction des résultats de la première étude, bien qu’on ait obtenu, dans les deux expériences, exactement les mêmes 70 % de garçons! Ainsi, pour seulement dix naissances, il aurait fallu 90 % de garçons pour que l’hypothèse du hasard puisse être écartée. Pourtant, le taux de 70 % obtenu dans la deuxième recherche est une reproduction plus proche du résultat, que les 90 % nécessaires pour que cette dernière soit statistiquement significative.
Par conséquent, alors que les p-values devraient être employées pour évaluer les données globales étayant l’existence d’un phénomène, elles ne devraient pas être utilisées pour définir si la reproduction d’un résultat expérimental est « réussie. » Au lieu de cela, une reproduction réussie devrait mettre en évidence un effet qui situe cette expérience dans la variabilité statistique prévue en fonction du résultat original, ou qui réalise un effet encore plus important pour des raisons explicables.
Il existe différents types de taille d’effet utilisés en sciences sociales, mais dans ce rapport, nous nous concentrerons sur la taille d’effet la plus communément utilisée pour évaluer les résultats de la vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More au SRI et au SAIC. Sa définition étant quelque peu technique, elle est donnée en annexe 1. Une explication plus intuitive sera proposée dans la prochaine sous-partie. A noter qu’une taille d’effet de 0 est conforme au hasard, et que, par convention, les scientifiques travaillant dans le domaine des sciences sociales ont décrété qu’une taille d’effet de 0,2 était petite, qu’elle était moyenne à 0,5 et grande à 0,8. Une taille d’effet moyenne est censée être évidente « à l’il nu » pour un observateur attentif, alors qu’une grande taille d’effet est censée être évidente pour n’importe quel observateur.
2.2.3 Système aléatoire et évaluation par classement
Chaque méthode statistique détermine, au départ, une définition de ce que l’on peut attendre d’un simple effet « au hasard » ou « par chance ». Sans mécanismes aléatoires de comparaison, il ne peut pas y avoir d’évaluation statistique.
Il n’existe pas de mécanismes aléatoires spécifiques des réponses obtenues lors d’expériences portant sur la connaissance anormale ; en d’autres termes, il n’y a pas de possibilité de définir ce que seraient ces réponses « par hasard ». Par conséquent, le mécanisme aléatoire étudié comparativement pour évaluer ces expériences porte sur le choix des cibles. Nous pouvons de cette façon comparer la réponse choisie par le sujet avec la cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). réelle et répondre à la question : « Si seul le hasard est en jeu, quelle est la probabilité qu’une cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). soit choisie et qu’elle corresponde à la bonne réponse ? ».
Dans cette perspective, une expérience correctement menée utilise un ensemble de cibles définies à l’avance. La cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). de chaque séance de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More est alors choisie aléatoirement, de telle façon que la probabilité d’obtenir chacune des cibles possibles soit connue.
Toutes les expériences de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More effectuées au SAIC et au SRI (sauf les toutes premières pour le SRI) ont employé une méthode statistique d’évaluation connue sous le nom d’évaluation par classement (Rank-Order Judging). Après une séance de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More (remote viewingLe Remote Viewing (vision à distance) est une technique utilisée lors de protocoles de parapsychologie en vu d'étudier les perceptions extra-sensorielles. Les techniques de vision à distance ont pour origine les travaux de René Warcollier. Elle ont ensuite été développées au sein du programme de vision à distance commandité par la CIA dans les années 1970. Jusqu'en 1995, les chercheurs qui ont participé à ce programme se sont efforcés d'utiliser les techniques de remote viewing afin de tenter de développer des applications du psi, en particulier dans le domaine du renseignement.), la description donnée par le sujet ainsi que cinq cibles potentielles sont données à un juge ignorant quelle est la vraie cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). (on l’appelle juge en aveugle) que le sujet devait décrire par connaissance anormale. Quatre de ce ces cibles sont donc des leurres.
Avant que l’expérience ne soit effectuée, chacune des cinq cibles a une chance égale d’être sélectionnée en tant que cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). que le sujet devra décrire. Le juge est invité à donner à chacune des cibles une note allant de un (signifiant que la description du sujet est proche de cette cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.).) à cinq (quand la description du sujet correspond peu à la cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.).).
La note donnée par le juge pour la cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). correcte, celle qui devait être décrite par le sujet psiIndividu qui semble produire des phénomènes psi de façon particulièrement intense ou fiable., correspond au nombre de points obtenus lors d’une séance de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More. Par le simple effet du hasard, la bonne cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). (celle décrite par le sujet psiIndividu qui semble produire des phénomènes psi de façon particulièrement intense ou fiable.) est notée selon une probabilité égale, puisque toutes les cibles ont la même probabilité d’être sélectionnées. Le classement moyen par le simple fait du hasard serait normalement de trois. Une connaissance anormale est mise en évidence quand le classement moyen sur une série d’essais est significativement inférieur à trois. (à noter qu’un classement en première position est le meilleur résultat possible pour chaque essai).
Cette méthode de notation est limitée car elle ne favorise pas la mise en évidence de ressemblance particulièrement nette entre la description du sujet et la cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.).. Une description qui décrit la cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). parfaitement aura en effet le même classement qu’une réponse qui contient seulement assez d’information pour sélectionner la cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). comme étant le meilleur choix parmi les cinq cibles potentielles. L’un des avantages de cette méthode est qu’elle reste valide même si le sujet connaît l’ensemble des cibles possibles. La probabilité d’une bonne correspondance, au premier coup et par hasard, reste d’une sur cinq. Ce point a son importance étant donné que les expériences postérieures à celles du SRI, et de plusieurs expériences du SAIC, ont employé le même jeu de photographies du National Geographic comme cibles. Par conséquent, si de telles précautions n’avaient pas été prises, les sujets habitués à ces expériences auraient pu se familiariser avec l’éventail des possibilités puisqu’on leur montrait la réponse à la fin de chaque session de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More.
Pour des raisons techniques, expliquées en annexe 1, la taille d’effet, pour une série de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More utilisant l’évaluation par classement, avec cinq choix est de (3,0 – classement moyen)/racine(2). Par conséquent, les petites, moyennes et grandes tailles d’effet (0,2, 0,5 et 0,8) correspondent aux classements moyens respectifs de 2,72, de 2,29 et de 1,87. A noter que la plus grande taille d’effet possible en utilisant cette méthode est de 1,4. Ce résultat serait obtenu si, à chaque séance de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More, le juge classait la bonne cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). en première position.
2.3 Problèmes méthodologiques
L’une des difficultés, lors de la conception d’une expérience, et quel que soit d’ailleurs le domaine scientifique, est l’exclusion des biaisPrésence de patterns ou de défauts particuliers pouvant introduire une modification arbitraire des résultats et faussant ainsi leur validité (ex : un dé non équilibré ayant tendance à faire sortir souvent le même chiffre). potentiels.
Dans les expériences de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More, des informations pourraient être obtenues par des biaisPrésence de patterns ou de défauts particuliers pouvant introduire une modification arbitraire des résultats et faussant ainsi leur validité (ex : un dé non équilibré ayant tendance à faire sortir souvent le même chiffre). sensoriels si des précautions appropriées n’étaient pas prises. Les premières expériences au SRI souffraient de certains de ces problèmes méthodologiques, mais les expériences postérieures du SRI et le travail du SAIC ont été effectués avec la rigueur méthodologique nécessaire, à quelques exceptions près, figurant dans les descriptions détaillées des expériences du SAIC proposées en annexe 2.
La liste suivante de biaisPrésence de patterns ou de défauts particuliers pouvant introduire une modification arbitraire des résultats et faussant ainsi leur validité (ex : un dé non équilibré ayant tendance à faire sortir souvent le même chiffre). potentiels montre la variété des difficultés qui doivent être prises en compte. Une expérience bien menée exige une réflexion approfondie et une planification rigoureuse :
Aucune des personnes ayant connaissance de la cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). choisie ne doit avoir eu de contact avec le sujet testé tant que la réponse de ce dernier n’a pas été mise en lieu sûr.
Aucune des personnes ayant connaissance de la cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). choisie, ou ne serait-ce que de la réussite ou de l’échec de la session, ne doit être en contact avec le juge tant que la phase de jugement n’est pas terminée.
Aucune des personnes ayant connaissance de la cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). choisie ne doit avoir accès à la réponse du sujet tant que l’évaluation n’est pas finie.
Les cibles et les leurres utilisés pour la phase de jugement doivent être sélectionnés par l’intermédiaire d’un dispositif de tirage aléatoire convenablement testé.
Deux jeux identiques de photographies des cibles doivent être utilisés, l’un pour l’expérience et l’autre pour la phase de jugement, de sorte qu’aucun indice (comme des empreintes digitales) ne puisse être transmis concernant la bonne cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). et pouvant aider le juge à l’identifier.
La fin d’une expérience doit être définie à l’avance de sorte que l’expérience ne doit pas être arrêtée quand les résultats s’avèrent concluants. Cela signifie qu’il faut indiquer le nombre d’essais à l’avance, bien que certaines analyses statistiques exigent ou permettent certaines règles spécifiques concernant l’arrêt des essais. L’essentiel est que ces règles soient définies à l’avance de telle manière qu’il n’y ait aucune ambiguïté concernant l’arrêt de l’expérience.
Les raisons pouvant donner lieu à l’exclusion de certaines données doivent être définies à l’avance, appliquées de façon homogène et ne doivent pas être dépendantes des données. Ainsi, une règle indiquant qu’un essai peut être abandonné si le sujet se sentait malade peut être légitime, mais seulement si l’essai était abandonnée avant que toute personne impliquée dans cette décision n’aie eu connaissance de la cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). correcte.
Les analyses statistiques à employer doivent être définies avant la collecte des données de sorte qu’une méthode plus favorable aux données ne puisse être choisie a posteriori. Si des méthodes d’analyse multiples sont employées, les conclusions doivent le mentionner.
2.4 « Preuve évidente »
Selon le dictionnaire Webster et dans le domaine légal, une « preuve évidente » (prima facie evidence) est « un fait ayant un tel degré de probabilité qu’il s’impose à moins que le contraire ne soit prouvé. » Il existe quelques exemples de visions à distance faites hors laboratoire qui semblent fournir un tel critère de preuve. Ce sont des exemples dans lesquels le commanditaire, ou un autre organisme gouvernemental, a demandé une session de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More d’un lieu, connu du commanditaire, dans le présent ou le futur, et lors de laquelle le sujet a fourni des détails bien au delà de ce qui pourrait être le fruit d’une déduction rationnelle. Deux exemples de ce type sont donnés par May (1995) où il s’avère que les résultats étaient si frappants qu’ils dépassaient de loin le phénomène observé en laboratoire. En utilisant une analyse à posteriori, le Dr. May a conclu que dans l’un de ces cas, le sujet psiIndividu qui semble produire des phénomènes psi de façon particulièrement intense ou fiable. a pu, à distance, décrire un générateur à micro-ondes avec 80 % d’exactitude, et que ce qu’il a dit était fiable à pratiquement 70 %. Les essais de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More en laboratoire montrent rarement ce niveau de résultat.
A noter que les méthodes statistiques standard ne peuvent pas être employées dans ces cas, car il n’existe pas de norme permettant une comparaison probabiliste. Mais la « preuve évidente » obtenue lors de sessions de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More en vue d’applications, ne peut pas être écartée comme étant sans importance juste parce que nous ne pouvons pas assigner des probabilités spécifiques aux résultats. Il est fondamental de s’assurer si l’information était ou non accessible par des moyens conventionnels. Dans la section 3, nous donnerons un exemple dans lequel un sujet a donné les noms de code d’un local secret dont il n’était même pas censé connaître l’existence. A supposer que les commanditaires étaient absolument certains que le sujet ne pouvait pas connaître ces noms de code par des biaisPrésence de patterns ou de défauts particuliers pouvant introduire une modification arbitraire des résultats et faussant ainsi leur validité (ex : un dé non équilibré ayant tendance à faire sortir souvent le même chiffre). conventionnels, alors, même si nous ne pouvons pas déterminer une probabilité exacte au fait qu’il les ait devinés correctement, nous pouvons convenir que cette probabilité s’avère très faible. Cela constitue une « preuve évidente », à moins qu’une explication alternative puisse être trouvée. De même, le sujet qui a décrit le générateur à micro-ondes savait seulement que la cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). était un site technique installé aux États-Unis. Il a cependant dessiné et décrit le générateur à micro-ondes, y compris sa fonction, sa taille approximative, et la façon dont il était installé et l’angle de divergence d’un faisceau de 30 degrés » (May, 1995, p. 15).
Les témoignages concernant les phénomènes psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi. souffrent souvent du même problème pour ce qui est de les considérer comme des preuves. La principale difficulté supplémentaire est que la « réponse » n’est pas bien définie à l’avance, contrairement aux tests de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More en vue d’application où le sujet fournit un ensemble défini d’informations sur demande. Par exemple, si un groupe de personnes rêve chaque nuit d’accidents d’avion, alors certains le feront évidemment la nuit précédent un accident d’avion important. Ces individus pourront interpréter la coïncidence comme étant significative. C’est la raison pour laquelle de nombreuses personnes pensent que les phénomènes psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi. relèvent du domaine de la croyance, plutôt que de celui de la science, car elles connaissaient généralement mieux les anecdotes et les témoignages que les résultats probants obtenus en laboratoire.
3.1 Évaluation des premiers succès opérationnels
Selon Puthoff et Targ (1975), la recherche scientifique menée au SRI n’aurait jamais pu obtenir des fonds sans trois succès opérationnels manifestes au cours des premiers jours du programme. Ceux-ci sont détaillés par Puthoff et Targ (1975) mais ces derniers ne définissent pas clairement la précision des résultats.
L’un de ces succès concernait un site de l’Ouest-Virginie. Au cours d’une session, deux sujets psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi. ont semble-t-il identifié un local souterrain secret. L’un d’entre eux aurait donné les mots de passe et nommé le personnel de ce site si précisément, que cela aurait déclenché une enquête pour déterminer l’origine de la fuite de cette information. En partant uniquement des coordonnées du site en question, le sujet aurait d’abord décrit le terrain situé en surface, puis il aurait décrit des détails du site souterrain caché.
Le même sujet a alors dit qu’il pourrait décrire un site similaire du bloc communiste, ce qu’il a fait avec un site localisé dans les Monts de l’Oural. Selon Puthoff et Targ « les deux rapports, pour le site de l’Ouest-Virginie et pour l’emplacement des Monts de l’Oural, ont été vérifiés par le personnel de l’organisation qui avait commandité ces recherches et il les a considérés comme corrects, dans l’ensemble » (P. 8).
Le troisième succès opérationnel, ayant fait l’objet d’un rapport, portait sur la description précise d’une grande grue et d’autres éléments présents sur un site de Semipalatinsk, en URSS. Le sujet a été une nouvelle fois uniquement informé des coordonnées géographiques du site et a été invité à décrire ce qui se trouvait à cet endroit.
Bien qu’une partie des informations provenant de ces exemples ait été confirmée comme tout à fait exacte,, l’évaluation des travaux opérationnels de ce type demeure délicat, en partie parce qu’il n’existe pas de possibilités de comparaison avec le hasard (comme c’est le cas en expériences contrôlées) et les avis des experts peuvent diverger.
Par exemple, un fonctionnaire du gouvernement qui a passé en revue le travail de Semipalatinsk a conclu que le sujet psiIndividu qui semble produire des phénomènes psi de façon particulièrement intense ou fiable. ne pouvait avoir dessiné la grande grue avec un portique à moins qu’il ne l’ait vue réellement par vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More, ou qu’il ait été informé de ce qu’il devait dessiner par quelqu’un connaissant le site. Pourtant, le même analyste a conclu que « la vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More du site par le sujet S1 s’était avérée être un échec » parce que « la seule preuve positive de la grue à portique sur rail était bien trop prépondérante par rapport à la grande quantité de preuves négatives relatées dans le corps de cette analyse ». En d’autres termes, l’analyste attendait, pour que la vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More soit « positive », qu’elle ne contienne que des informations exactes.
Une autre difficulté concernant l’évaluation de ce travail opérationnel est qu’il n’y a aucun moyen de savoir avec certitude si le sujet n’a pas parlé avec quelqu’un qui connaissait le site, si improbable que cette possibilité puisse paraître. En conclusion, nous ne savons pas dans quelle mesure les résultats de ces rapports n’ont pas été sélectivement choisis comme étant corrects. Ce problème peut être évité avec des expériences contrôlées conçues convenablement.
3.2 Les premières recherches scientifique au SRI
De 1974 au début de l’année 1975, un certain nombre d’expériences contrôlées ont été mise en place afin de déterminer si diverses cibles pourraient être décrites avec succès par vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More. Les résultats rapportés par Puthoff et Targ (1975) indiquent un succès avec un large éventail de cibles, allant de « cibles techniques », comme une photocopieuse, à des sites naturels, comme une piscine. Mais cette expérience, et d’autres qui suivront, ont été critiquées pour des raisons statistiques et méthodologiques ; nous décrirons brièvement l’une de ces expériences et ses critiques pour montrer le genre de problèmes rencontrés lors des premiers travaux scientifique au SRI.
Les plus grandes séries de sessions qui se sont déroulées, de 1973 à 1975, concernaient la vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More de sites naturels. Pour chaque session, des lieux ont été tirés au hasard parmi un ensemble de 100 cibles potentielles. Ils furent choisis « sans remise »( without replacement), ce qui signifie que les lieux déjà sélectionnés ne furent pas réutilisés. Cette série utilisa huit sujets psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi., dont deux fournis par le gouvernement. De nombreuses descriptions ont montré un degré de correspondance élevé sur le plan qualitatif, et les résultats statistiques globaux furent tout à fait convaincants pour la plupart des sujets psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi..
Ces expériences ont été critiquées sur un certain nombre de points, notamment sur le choix des cibles, sans remise, et la méthode d’évaluation statistique employée. Les résultats ont été évalués lors d’une phase de jugement en aveugle, en tentant de relier la cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). avec la transcription des réponses des sujets psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi.. Une grande partie des appariements fut positif. Mais les critiques ont également porté sur quelques concordances réussies qui auraient pu être obtenues à partir d’indices provenant de la transcription du matériel. Par exemple, un sujet avait mentionné lors d’une session quelle avait été la cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). de la session précédente. Les lieux ayant été choisis sans remise, connaître ce qu’a pu être la réponse un jour donné exclut cet emplacement-cible d’être la réponse les autres jours. Il n’y a pas de possibilité de déterminer dans quelle mesure ces problèmes ont influencé les résultats. Ces critiques, et celles qui suivirent, ont eu pour conséquence une amélioration sensible de la méthodologie utilisée lors de ces expériences.
3.3 Analyse globale des expériences effectuées au SRI de 1973 à 1988
Une analyse a été faite de toutes les expériences effectuées, au SRI, depuis 1973 et jusqu’en 1988 (May et al, 1988). L’analyse fut fondée sur les 154 expériences réalisées pendant cette période, composées de plus de 26.000 essais individuels. Parmi ceux-ci, environ 20.000 étaient du type « choix forcé » et un peu plus de mille étaient des tests de visions à distance en laboratoire. 227 sujets ont été impliqués dans ces expériences.
Les résultats statistiques de ces expériences sont tellement imposants que des résultats aussi significatifs ne pourraient se produire qu’une fois sur 10 puissance 20 si le hasard seul en était à l’origine (c.-à-d. que la p-value est inférieure à 10-20 (10 à la puissance -20)). Évidemment, d’autres explications que le hasard doivent alors être envisagées. Le psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi. peut ne pas être l’unique possibilité, et cela d’autant plus que certains des premiers travaux comportaient des problèmes méthodologiques comme nous l’avons vu. Cependant, le fait que la même taille d’effet se soit maintenue dans les expériences postérieures, et ne présentant pas ces problèmes méthodologiques, confirme que les problèmes méthodologiques ne peuvent expliquer ces résultats. De plus, un groupe de sujets doués (identifiés G1 dans ce rapport) obtenait des effets plus importants que l’ensemble des sujets. Selon le Dr. May, la majorité des expériences conduites avec ce groupe ont été menées plus tardivement dans le programme, après que la méthodologie se soit sensiblement améliorée.
Outre les résultats statistiques, un certain nombre d’autres questions et de paramètres furent examinés et testés. En voici un résumé :
1. Les expériences de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More utilisant des protocoles avec des « réponses libres » (dans lesquelles les sujets décrivent librement une cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.).) étaient beaucoup plus réussies que les expériences à « choix forcé » (au cours desquelles les sujets devaient choisir parmi un ensemble restreint de possibilités).
2. Un groupe de six sujets sélectionnés avait des performances dépassant de loin celles des sujets non sélectionnés. Ces mêmes individus réussissaient de façon homogène et mieux que d’autres sujets lors des différents protocoles, aboutissant ainsi à une reproductibilitéPossibilité de reproduire des résultats identiques ou similaires dans des expérimentations de même type. qui permet de justifier la validité des résultats. Si des problèmes méthodologiques étaient responsables des résultats, ils ne devraient pas affecter ce groupe différemment des autres.
3. La mise en place d’un système de sélection des sujets doués sur une population importante a montré qu’environ un pour cent de ceux qui se sont volontairement proposés pour être testés furent doués en vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More. Ceci indique que la vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More est une aptitude qui diffère d’un individu à l’autre, tout comme les aptitudes sportives ou le talent musical (les résultats des tests effectués lors de cette sélection n’ont pas été inclus dans l’analyse formelle car les conditions n’étaient pas suffisamment contrôlées).
4. Ni la pratique, ni un type de technique d’entraînement particulier n’a réussi à améliorer les facultés de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More. Il s’avère qu’il est plus facile de trouver, que de former, de bons sujets psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi..
5. Il n’est pas évident que le feedback1. rétroaction de linformation dans les systèmes cybernétiques ; information renvoyée au sujet sur nimporte quelle mesure prise sur lui-même (physiologique, psychologique, tests psi) ; 2. moyen utilisé pour lui redonner cette information (ex : feedback auditif, feedback visuel, etc.). (montrer au sujet la bonne réponse après une session) soit nécessaire, mais il semble fournir une aide psychologique qui peut accroître les performances obtenues.
6. La distance entre la cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). et le sujet ne semble pas affecter la qualité de la vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More.
7. L’isolation électromagnétique ne semble pas inhiber les performances.
8. Il est patent que la précognitionLa précognition est la connaissance dun événement futur qui ne pourrait être ni prédit ni inféré par des moyens normaux., dans laquelle la cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). est choisie après que le sujet en ait donné sa description, fonctionne également.
9. Il n’y a aucune preuve en faveur d’une perturbation anormale (psychokinèseCapacité à influencer mentalement un objet, un processus ou un système sans lutilisation de mécanismes ou dénergies connues. On distingue la bio-psychokinèse , la micro-psychokinèse et la macro-psychokinèse .), c.-à-d. d’une interaction physique avec l’environnement, par des moyens psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi..
3.4 Conformité avec d’autres laboratoires dans la même période
L’un des indices permettant d’identifier un phénomène comme existant, est qu’il est reproductible par des chercheurs différents, travaillant dans des conditions similaires. Les résultats de l’analyse globale du SRI sont conformes aux résultats d’expériences identiques pratiquées dans d’autres laboratoires. Par exemple, une vue d’ensemble des expériences de précognitionLa précognition est la connaissance dun événement futur qui ne pourrait être ni prédit ni inféré par des moyens normaux. à choix forcé (Honorton et Ferrari, 1989) donne une taille d’effet moyenne par expérimentateur de 0,033, tandis que toutes les expériences à choix forcé du SRI ont abouti à un effet de taille d’effet proche de 0,052. La comparaison n’est pas idéale puisque les expériences à « choix forcé » du SRI n’étaient pas nécessairement précognitives et utilisaient des types de support de cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). différents des expériences standards de divination de cartes.
Des expériences de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More utilisant des méthodologies fiables n’ont pas été mises en place par d’autres laboratoires, mais un protocole similaire appelé GanzfeldLe Ganzfeld (terme allemand qui signifie "champ sensoriel uniforme") est un protocole dinduction détat hypnagogique pour les expériences de télépathie. Le Ganzfeld est le protocole le plus utilisé actuellement en parapsychologie expérimentale. Il a été tout d'abord développé par Charles Honorton dans les années 1970. (décrit plus en détail dans la section 5) s’est montré également concluant. La plus grande série d’expériences de GanzfeldLe Ganzfeld (terme allemand qui signifie "champ sensoriel uniforme") est un protocole dinduction détat hypnagogique pour les expériences de télépathie. Le Ganzfeld est le protocole le plus utilisé actuellement en parapsychologie expérimentale. Il a été tout d'abord développé par Charles Honorton dans les années 1970. a été effectuée de 1983 à 1989 au Psychophysical Research Laboratories ( PRL, (Laboratoire de Recherches Psychophysiques) de Princeton, dans le New Jersey. Ces expériences ont également permis de différencier les sujets débutants des sujets entraînés. La taille d’effet globale pour les expériences de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More, avec des sujets débutants, au SRI, était de 0,164, alors que la taille d’effet des sujets débutants avec le protocole ganzfeldLe Ganzfeld (terme allemand qui signifie "champ sensoriel uniforme") est un protocole dinduction détat hypnagogique pour les expériences de télépathie. Le Ganzfeld est le protocole le plus utilisé actuellement en parapsychologie expérimentale. Il a été tout d'abord développé par Charles Honorton dans les années 1970., au PRL, était de 0,17. Pour les sujets entraînés du SRI, la taille d’effet globale était de 0,385 ; pour les sujets entraînés des expériences de GanzfeldLe Ganzfeld (terme allemand qui signifie "champ sensoriel uniforme") est un protocole dinduction détat hypnagogique pour les expériences de télépathie. Le Ganzfeld est le protocole le plus utilisé actuellement en parapsychologie expérimentale. Il a été tout d'abord développé par Charles Honorton dans les années 1970., elle était de 0,35. Ces résultats, particulièrement proches dans ces différents laboratoires, contribuent à réfuter l’idée selon laquelle les expériences réussies dans ces centres de recherche soient le résultat de fraudes, de protocoles approximatifs ou de biaisPrésence de patterns ou de défauts particuliers pouvant introduire une modification arbitraire des résultats et faussant ainsi leur validité (ex : un dé non équilibré ayant tendance à faire sortir souvent le même chiffre). méthodologiques et propose un aperçu de ce qu’on peut attendre lors des futures expériences.
4.1 Une vue d’ensemble
Nous avons décidé de nous concentrer davantage sur les expériences effectuées au Science Applications International Corporation (SAIC), car elles fournissent un ensemble plus large d’expériences à étudier en détail. Ces expériences ont été supervisées par un comité scientifique, constitué d’experts provenant de disciplines variées, comprenant un prix Nobel de Physique, des professeurs de statistiques reconnus internationalement, des psychologues, des neurologues et des astronomes ainsi qu’un docteur en médecine, Major à la retraite, de l’armée américaine. De plus, nous avons eu accès, de façon exhaustive, à l’ensemble des données provenant des expériences menées au SAIC, ce qui ne fut pas le cas des expériences conduites au SRI. Quels que soient les détails non indiqués dans les rapports écrits, nous avons pu nous les procurer auprès du directeur de ces recherches, le Dr Edwin May.
Dans un mémo daté du 25 juillet 1995, le Dr. Edwin May a énuméré l’ensemble des expériences conduites au SAIC. Dix expériences ont ainsi été conçues pour étudier les phénomènes psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi.. Elles reprenaient notamment certaines questions ouvertes par les travaux effectués au SRI et dans d’autres laboratoires et n’avaient pas simplement pour objectif de fournir des preuves supplémentaires de l’existence du psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi.. Certaines de ces expériences utilisaient les mêmes protocoles que les expériences de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More du SRI et nous les examinerons afin de voir si elles ont reproduit les résultats du SRI. Nous examinerons aussi quelles nouvelles connaissances ont pu être obtenues à partir des résultats des travaux du SAIC.
4.2 Les Dix Expériences
Sur les dix expériences menées au SAIC, six d’entre elles ont utilisé des protocoles de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More. Plutôt que de présenter en détail ces expériences dans le corps de ce rapport, nous proposons une courte description de ces expériences en annexe. Ce qui suit est une discussion de la méthodologie et des résultats globaux de ces expériences. En raison des différences fondamentales entre les protocoles de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More et les autres types d’expériences, nous les traiterons séparément.
Dans son mémo du 25 juillet 1995, le Dr. May a fourni des détails concernant ces dix expériences, incluant leur titre, leur nombre d’essais, la taille d’effet et la p-value globale obtenue pour chacune d’entre elles. Sa liste était en ordre chronologique. Elle est reproduite dans le tableau 1, en utilisant son système de numération, les expériences étant classées par type. Les évaluations des tailles d’effet sont basées sur un nombre limité d’essais. Elles sont donc accompagnées d’un intervalle montrant la fourchette probable de l’effet réel (par exemple 0,124+/-0,071 correspond à une fourchette de 0,053 à 0,195). Nous rappelons qu’une taille d’effet de 0 correspond au simple effet du hasard, alors qu’une taille d’effet positive indique généralement des résultats probants.
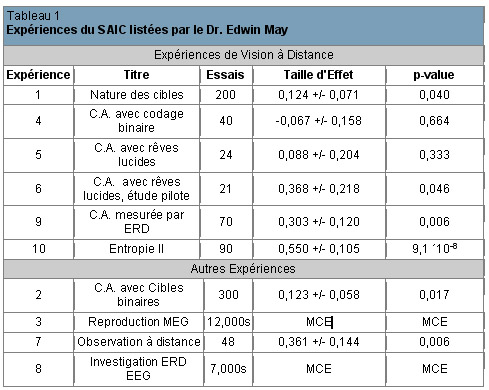
4.3 Evaluation des expériences de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More selon l’homogénéité des sessions
Le tableau 1 permet une évaluation globale des résultats de chaque expérience, mais il le fait au détriment des informations concernant la spécificité des sujets et le type de cibles utilisées. Pour mieux comprendre les phénomènes étudiés, il est nécessaire de regarder en détail les résultats, en particulier l’homogénéité des procédures. Il est également essentiel de pouvoir évaluer l’impact de tout problème méthodologique potentiel. Par exemple, dans une des expériences pilote (E6, C.A. sur les rêves lucides) les sujets ont été autorisés à emmener les cibles chez eux dans des enveloppes scellées. Le tableau 2 présente les tailles d’effet au niveau le plus homogène possible en fonction des informations données. Des descriptions de ces expériences sont disponibles en annexe 2. Les tailles d’effet globales de chaque sujet psiIndividu qui semble produire des phénomènes psi de façon particulièrement intense ou fiable. et la taille d’effet totale de chaque expérience sont pondérées selon le nombre d’essais de façon à ce que chaque essai ait une pondération égale.
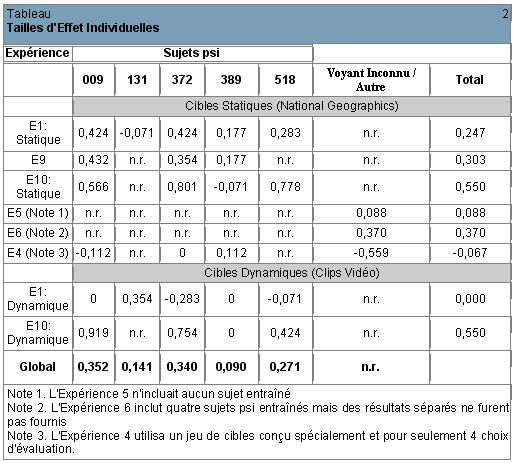
4.4 Uniformité et ReproductibilitéPossibilité de reproduire des résultats identiques ou similaires dans des expérimentations de même type. des résultats de Vision à DistancePerception extra sensorielle d’un lieu situé à distance du récepteur. More
La reproductibilitéPossibilité de reproduire des résultats identiques ou similaires dans des expérimentations de même type. est l’une des caractéristiques principales de la recherche scientifique. Les phénomènes dotés d’une variabilité statistique, qu’il s’agisse du taux de home-runs au base-ball, de l’action d’un traitement chimiothérapique ou de phénomènes psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi., doivent présenter un niveau de succès constant, sur le long terme, lors de reproductions d’expériences dans des conditions similaires. Les expériences de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More ne font pas exception à cette règle. Nous rappelons que de tels résultats ne devraient pas se reproduire avec un tel degré de précision en raison de la variabilité statistique, de la même façon que nous n’obtenons pas systématiquement cinq pile et cinq faces si nous lançons une pièce de monnaie dix fois de suite.
L’analyse des expériences du SRI, effectuées en 1988, portait sur les sessions de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More de six sujets psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi. « experts » – les numéros 002, 009, 131, 372, 414 et 504. Ces six individus ont participé à 196 sessions. La taille d’effet obtenue fut de 0,385 (May et al, 1988, p. 13). L’analyse du SRI n’inclut pas des informations individuelles propre à chaque sujet, ni d’informations sur le nombre de sessions faites sur cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). statique ou sur cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). dynamique pour l’ensemble des 196 sessions. Un rapport fourni à l’équipe de contrôle (May, Lantz et Piantineda, 1994) inclut une expérience supplémentaire menée après que la revue de contrôle de 1988 ait été faite. Dans cette dernière, le sujet 009 a participé à 40 sessions. La taille d’effet du sujet 009 à ces sessions était de 0,363. Aucun des six autres experts du SRI n’y a participé.
Les mêmes numéros identifiant les sujets ont été employés au SAIC et nous pouvons ainsi comparer la performance de ces individus, tant au SRI qu’au SAIC. Sur les six sujets, trois ont été spécifiquement mentionnés comme participant aux expériences de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More du SAIC. Comme on peut le voir dans le tableau 2, les sujets 009, 131 et 372 ont tous participé à l’expérience 1 et les sujets 009 et 372 ont également participé aux expériences 4, 9 et 10.
Les tailles d’effet globales pour deux des trois sujets, 009 et 372, étaient très proches de la taille d’effet de 0,385 du SRI, avec respectivement 0,35 et 0,34, et la taille d’effet de 0,35 pour le sujet 009 était très voisine de sa taille d’effet de 0,363 du rapport de May, Lantz et Piantineda (1994). Par conséquent, nous observons, pour ces individus, des résultats qui sont supérieurs au hasard et cela de façon répétée et reproductible. Un effet de cette importance devrait, en effet, être assez fiable pour être reproduit dans n’importe quelle expérience correctement menée, avec suffisamment d’essais pour obtenir la reproductibilitéPossibilité de reproduire des résultats identiques ou similaires dans des expérimentations de même type. statistique de longue durée exigée pour éliminer le hasard.
Il est également important de souligner que les sujets 009 et 372 ont été performants, et non-performants, lors des mêmes expériences. La corrélation entre leurs tailles d’effet respectives lors des expériences est de 0,901, ce qui est très proche d’une corrélation parfaite de 1,0. On peut se demander si la cause d’une telle uniformité n’est pas la nature des expériences, un heureux hasard statistique ou quelque problème méthodologique conduisant ces deux individus à des performances si proches. Si des problèmes méthodologiques sont à l’origine de ces résultats, alors ils doivent être particulièrement subtils car les méthodologies de plusieurs expériences étaient identiques tandis que leurs résultats différaient. Ainsi, les procédures des sessions avec les cibles statiques et dynamiques de l’expérience 1 étaient presque identiques, pourtant les cibles dynamiques n’ont pas mis en évidence de capacités psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi. (p-value = 0,50) alors que ce fut le cas avec les cibles statiques (p-value = 0,0073). Par conséquent, un problème méthodologique aurait dû affecter différemment les résultats sur deux types de cibles, bien que l’attribution du type de cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). ait été aléatoire sur l’ensemble des sessions.
4.5 Problèmes méthodologiques dans les expériences de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More au SAIC
Comme indiqué dans la section 2.3, un certain nombre de considérations méthodologiques sont requises pour mener à bien une expérience de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More dans de bonnes conditions. Les informations nécessaires pour déterminer précisément ces conditions, lors des expériences, étaient généralement indiquées dans les rapports, mais j’ai parfois consulté le Dr. May pour obtenir des informations complémentaires. Une analyse de l’expérience 1 sera donnée comme exemple de la façon dont les problèmes méthodologiques de la section 2.3 ont été abordés.
Dans cette expérience, les sujets psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi. ont travaillé de leurs domiciles (à New York, au Kansas, en Californie et en Virginie). Le Dr. Nevin Lantz, qui résidait en Pennsylvanie, était l’expérimentateur principal. Après chaque session, les voyants envoyaient par fax leur réponse au Dr. Lantz et postaient leur version originale au SAIC. Lors de la réception du fax, le Dr. Lantz envoyait la réponse correcte au sujet. Les sujets étaient censés expédier leurs réponses originales au SAIC immédiatement après les avoir envoyées, par fax, au Dr. Lantz. Selon le Dr. May, les version faxées étaient envoyées après que les originaux aient été postés afin de s’assurer que ces derniers avaient été envoyés sans aucun changement. Voici comment les autres problèmes méthodologiques de la section 2.3 ont été traités :
Aucune des personnes ayant connaissance de la cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). choisie ne doit avoir eu de contact avec le sujet testé tant que la réponse de ce dernier n’a pas été mise en lieu sûr.
Aucune des personnes impliquées dans l’expérience n’a eu de contact avec les sujets puisqu’ils n’étaient pas à proximité du SAIC ou de la maison du Dr. Lantz en Pennsylvanie.
Aucune des personnes ayant connaissance de la cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). choisie, ou ne serait-ce que de la réussite ou de l’échec de la session, ne doit être en contact avec le juge tant que la phase de jugement n’est pas terminée.
Le Dr. Lantz et les différents sujets étaient les seuls à connaître les réponses correctes, et selon le Dr. May, elles n’ont eu aucun contact avec le juge pendant la durée de cette expérience.
Aucune des personnes ayant connaissance de la cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). choisie ne doit avoir accès à la réponse du sujet tant que l’évaluation n’est pas finie.
Puisque seuls les voyants et le Dr. Lantz connaissaient la cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). correcte, et puisque les réponses furent expédiées au SAIC par les sujets psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi. avant qu’ils n’aient reçu les réponses, cette condition semble avoir été respectée.
Les cibles et les leurres utilisés pour la phase de jugement doivent être sélectionnés par l’intermédiaire d’un dispositif de tirage aléatoire convenablement testé.
Ce fut une pratique standard, tant au SRI qu’au SAIC.
Deux jeux identiques de photographies des cibles doivent être utilisés, l’un pour l’expérience et l’autre pour la phase de jugement, de sorte qu’aucun indice (comme des empreintes digitales) ne puisse être transmis concernant la bonne cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). et pouvant aider le juge à l’identifier.
Ce fut fait. Le Dr. Lantz a conservé le jeu utilisé pendant l’expérience, tandis que le jeu utilisé pour juger était conservé au SAIC en Californie.
La fin d’une expérience doit être définie à l’avance de sorte que l’expérience ne doit pas être arrêtée quand les résultats s’avèrent concluants. Cela signifie qu’il faut indiquer le nombre d’essais à l’avance, bien que certaines analyses statistiques exigent ou permettent certaines règles spécifiques concernant l’arrêt des essais. L’essentiel est que ces règles soient définies à l’avance de telle manière qu’il n’y ait aucune ambiguïté concernant l’arrêt de l’expérience.
Il a été décidé à l’avance que chaque voyant contribuerait à 40 essais, dix dans chacune des quatre conditions (toutes les combinaisons agentDans les cas spontanés, la personne vivant lévénement dont le récepteur va recevoir linformation ; dans les expérimentations de télépathie, lémetteur ; dans la psychokinèse :le sujet, considéré comme source du psi./pas d’agentDans les cas spontanés, la personne vivant lévénement dont le récepteur va recevoir linformation ; dans les expérimentations de télépathie, lémetteur ; dans la psychokinèse :le sujet, considéré comme source du psi. et statique/dynamique). Toutes les sessions ont respecté ce principe.
Les raisons pouvant donner lieu à l’exclusion de certaines données doivent être définies à l’avance, appliquées de façon homogène et ne doivent pas être dépendantes des données. Ainsi, une règle indiquant qu’un essai peut être abandonné si le sujet se sentait malade peut être légitime, mais seulement si l’essai était abandonné avant que toute personne impliquée dans cette décision n’ait eu connaissance de la cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). correcte.
Aucune raison de cet ordre n’a été donnée, pas plus qu’il n’y eut mention qu’une session fut abandonnée en cours ou rejetée.
Les analyses statistiques à employer doivent être définies avant la collecte des données de sorte qu’une méthode plus favorable aux données ne puisse être choisie a posteriori. Si des méthodes d’analyse multiples sont employées, les conclusions doivent le mentionner.
L’évaluation standard par classement ordonné avait été planifiée, avec des résultats rapportés séparément pour chacune des quatre conditions de l’expérience et pour chaque sujet psiIndividu qui semble produire des phénomènes psi de façon particulièrement intense ou fiable.. Ainsi, 20 tailles d’effet furent rapportées, quatre pour chacun des cinq sujets.
4.6 Qu’a t-on appris au SAIC ?
4.6.1 Le choix des cibles
Au-delà de la question de l’existence du psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi., les expériences effectuées au SAIC ont été conçues afin de tester un certain nombre d’hypothèses. Les expériences 1 et 10 étaient toutes deux conçues pour déterminer s’il y avait un rapport entre un changement au niveau de l’entropie visuelle des cibles et la réussite de la vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More.
Chacun de nos cinq sens détecte des variations. Notre vision est plus facilement attirée par quelque chose qui se déplace, et si nos yeux restent complètement immobiles, nous cessons en partie de voir. De même, nous entendons selon des variations au niveau des déplacements d’air, et notre attention est attirée par les variations sonores soudaines. Les autres sens se comportent de la même façon. Il est donc raisonnable de penser que s’il existe réellement un « sens psi », alors il doit fonctionner de la même façon.
Les expériences 1 et 10 ont été conçues pour examiner si la qualité de la vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More serait liée à un type particulier de changement du matériel au niveau des cibles, à savoir un changement de « l’entropie visuelle » ; Une cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). avec un degré élevé de changement serait une cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). dans laquelle les couleurs varient considérablement sur l’ensemble de la cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.).. Une explication détaillée peut être trouvée dans les rapports du SAIC sur cette expérience, ou dans l’article « Entropie de Shannon : une possible propriété intrinsèque de la cible » de May, Spottiswoode et James dans le « Journal of Parapsychology » de décembre 1994. Une corrélation entre une variation de l’entropie de la cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). et la qualité de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More a été obtenue. Ce résultat s’est présenté initialement dans l’expérience 1 et a été reproduite dans l’expérience 10. Une étude de simulation répartissant des cibles aléatoirement choisies aux réponses a prouvé qu’il était improbable que ce soit un artefact produit par la complexité de la cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). ou d’autres dispositifs.
Il est pertinent de s’interroger sur les conséquences de tels résultats sur le fonctionnement du psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi.. Les physiciens étudient actuellement le concept du temps, et ne peuvent éliminer a priori la précognitionLa précognition est la connaissance dun événement futur qui ne pourrait être ni prédit ni inféré par des moyens normaux. car elle n’est pas contredite dans l’état actuel des connaissances. Peut-être avons-nous vraiment un sens psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi., tout comme nos autres sens, et qu’il fonctionne en « scannant » le futur à la recherche de changements majeurs tout comme nos yeux balayent l’environnement à la recherche d’un changement visuel et que nos oreilles sont sensibles aux variations sonores.
Cette hypothèse est en adéquation avec les témoignages de précognitionLa précognition est la connaissance dun événement futur qui ne pourrait être ni prédit ni inféré par des moyens normaux. qui concernent généralement des événements impliquant des évènements de vie majeurs. La vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More, en laboratoire, pourrait fonctionner en partie grâce à une personne amenant le sujet à se focaliser sur un point particulier du futur, celui dans lequel il ou elle reçoit la réponse de l’expérience. Il pourrait être possible que ce même sens puisse également scanner l’environnement en temps réel pour y détecter un changement.
Une autre hypothèse, mise en avant au SAIC, est que les expériences de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More de laboratoire, pour être réussies, doivent proposer un éventail de cibles potentielles ni trop étroit ni trop large, au niveau de la quantité d’éléments possibles au sein des cibles. Ils ont appelé ce paramètre la « largeur de bande du paquet de cibles » (target-pool bandwidth), défini comme étant le nombre d’éléments cognitifs différenciables. Les chercheurs ont ainsi supposé que si le paquet de cibles potentielles était trop restreint, le sujet verrait le jeu entier et ne pourrait pas distinguer cette information de l’information psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi.. Si le paquet de cibles était trop important, le sujet n’aurait aucun moyen d’obtenir une vision d’ensemble.
La combinaison de ces deux facteurs semble indiquer qu’un bon jeu de cibles devrait contenir des cibles avec une variation élevée au niveau de l’entropie visuelle, mais que ce jeu devrait aussi contenir un ensemble de possibilités de taille moyenne. Le jeu de 100 photographies du « National Geographic » utilisé pendant la période tardive au SRI et au SAIC a pu accidentellement présenter ces paramètres.
4.6.2. « Regard à Distance » (Remote Staring)
L’expérience 7, décrite dans l’annexe 2, mène à des résultats très différents des sessions de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More classiques. Cette expérience, conçue pour tester des hypothèses provenant de l’ancienne Union Soviétique et de quelques chercheurs américains, supposait que des individus pourraient avoir une influence sur la physiologie d’autres sujets, et cela à distance. Cette recherche était constituée de deux réplications identiques de la même expérience. Elles furent toutes deux réussies d’un point de vue statistique. En d’autres termes, il s’est avéré que certaines mesures physiologiques d’un sujet ont été modifiées quand ce dernier était observé par une personne située à distance, dans une salle éloignée. Si ces résultats se confirment, ils pourraient justifier la rumeur selon laquelle certaines personnes ont l’impression de savoir quand on les observe alors qu’elles sont de dos.
4.6.3 Amélioration de la Divination par informatique binaire
L’expérience 2 était également très différente des expériences de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More classiques, bien qu’elle ait été aussi conçue pour étudier la connaissance anormale. Trois sujets ont essayé d’employer une technique d’amélioration statistique pour accroître la faculté de deviner des cibles à choix forcé à deux choix possibles. Cette expérience par ordinateur a mis en évidence que pour un sujet, l’estimation a été effectivement augmentée d’un taux brut à peine supérieur au hasard (51,6% au lieu de 50%) à un taux amélioré de 76 %. La méthode fut cepend extrêmement inefficace, et il est difficile d’imaginer des applications pratiques pour cette faculté, à supposer qu’elle existe.
5.1. Une approche similaire : les expériences de GanzfeldLe Ganzfeld (terme allemand qui signifie "champ sensoriel uniforme") est un protocole dinduction détat hypnagogique pour les expériences de télépathie. Le Ganzfeld est le protocole le plus utilisé actuellement en parapsychologie expérimentale. Il a été tout d'abord développé par Charles Honorton dans les années 1970.
Alors que les protocoles de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More ont été l’activité principale au SRI et au SAIC, d’autres chercheurs ont employé une technique analogue pour étudier la connaissance anormale, appelée le GanzfeldLe Ganzfeld (terme allemand qui signifie "champ sensoriel uniforme") est un protocole dinduction détat hypnagogique pour les expériences de télépathie. Le Ganzfeld est le protocole le plus utilisé actuellement en parapsychologie expérimentale. Il a été tout d'abord développé par Charles Honorton dans les années 1970.. Comme indiqué dans le rapport final du SAIC du 29 septembre 1994, les expériences de GanzfeldLe Ganzfeld (terme allemand qui signifie "champ sensoriel uniforme") est un protocole dinduction détat hypnagogique pour les expériences de télépathie. Le Ganzfeld est le protocole le plus utilisé actuellement en parapsychologie expérimentale. Il a été tout d'abord développé par Charles Honorton dans les années 1970. diffèrent de la vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More sur trois points fondamentaux. Tout d’abord, un état de conscience légèrement modifié est utilisé, en second lieu, des agents (sender) sont habituellement employés, de sorte que la télépathieLa télépathie désigne un échange dinformations entre deux personnes nimpliquant aucune interaction sensorielle ou énergétique connue. est la modalité d’intéraction principale, et troisièmement, les percipients (receiver) font eux-même l’évaluation de la période de jugement, et cela juste après la session, ce qui évite d’utiliser un juge indépendant.
Les expériences de GanzfeldLe Ganzfeld (terme allemand qui signifie "champ sensoriel uniforme") est un protocole dinduction détat hypnagogique pour les expériences de télépathie. Le Ganzfeld est le protocole le plus utilisé actuellement en parapsychologie expérimentale. Il a été tout d'abord développé par Charles Honorton dans les années 1970. menées au laboratoire de recherches psychophysiques (Psychophysical Research
Laboratories ou PRL) ont déjà été mentionnées à la section 3.4. Depuis la publication de ces résultats, d’autres laboratoires ont également mené des expériences de GanzfeldLe Ganzfeld (terme allemand qui signifie "champ sensoriel uniforme") est un protocole dinduction détat hypnagogique pour les expériences de télépathie. Le Ganzfeld est le protocole le plus utilisé actuellement en parapsychologie expérimentale. Il a été tout d'abord développé par Charles Honorton dans les années 1970.. Lors du congrès annuel de la Parapsychological AssociationLa Parapsychological Association (PA) est une organisation internationale constituée de scientifiques et d'universitaires qui étudient les phénomènes psi, comme la télépathie, la clairvoyance, la psychokinèse, la guérison psychique ou la précognition. La Parapsychological Association est reconnue comme une association scientifique à part entière, étant membre de l'AAAS depuis 1969. C'est le plus important organisme de recherche en parapsychologie. La plupart des parapsychologues sont membre de PA. elle permet de féderer l'ensemble des chercheurs travaillant dans le domaine de la parapsychologie et organise chaque année un congrès où sont publiées les recherches scientifiques des parapsychologues. Elle a pour objectif de promouvoir l'approche scientifique et objective des phénomènes psi et ses membres obeissent à une charte de déontologie., en 1995, trois nouvelles réplications ont été rapportées, toutes publiées dans les actes et revues par le comité de lecture du congrès.
Les expériences de GanzfeldLe Ganzfeld (terme allemand qui signifie "champ sensoriel uniforme") est un protocole dinduction détat hypnagogique pour les expériences de télépathie. Le Ganzfeld est le protocole le plus utilisé actuellement en parapsychologie expérimentale. Il a été tout d'abord développé par Charles Honorton dans les années 1970. diffèrent également au niveau de la méthode d’analyse utilisée. A la place de la méthode de somme des classements des différentes sessions, on ne garde comme essais concluants que ceux où la bonne cibleDans lESP, lobjet ou lévénement que le récepteur cherche à deviner (cartes-cible, image-cible, sites-cible) ; dans la PK, lobjet, le processus ou le système que le sujet cherche à influencer (système-cible : souris, GNA, dés, etc.). est classée en premier. Quatre choix sont proposés au lieu des cinq utilisés au SRI et au SAIC. Ainsi, le hasard devrait donner lieu à des résultats probants dans seulement 25% des cas (une chance sur quatre).
5.2 Les résultats du GanzfeldLe Ganzfeld (terme allemand qui signifie "champ sensoriel uniforme") est un protocole dinduction détat hypnagogique pour les expériences de télépathie. Le Ganzfeld est le protocole le plus utilisé actuellement en parapsychologie expérimentale. Il a été tout d'abord développé par Charles Honorton dans les années 1970. dans quatre laboratoires
Lorsqu’ils ont publié les résultats du GanzfeldLe Ganzfeld (terme allemand qui signifie "champ sensoriel uniforme") est un protocole dinduction détat hypnagogique pour les expériences de télépathie. Le Ganzfeld est le protocole le plus utilisé actuellement en parapsychologie expérimentale. Il a été tout d'abord développé par Charles Honorton dans les années 1970. au PRL, Bem et Honorton (1994) ont exclu une des recherches de l’analyse globale pour des raisons méthodologiques. Ils ont constaté que les recherches restantes présentaient 106 succès sur 329 sessions, soit un taux de succès de 32,2 % alors que un taux de 25 % était prévu par le simple fait du hasard. La p-value correspondante était de 0,002. Comme nous l’avons déjà dit, la reproductibilitéPossibilité de reproduire des résultats identiques ou similaires dans des expérimentations de même type. définit l’approche scientifique. Ce résultat a aujourd’hui été reproduit par trois autres laboratoires.
Bierman (1995) a publié quatre séries d’expériences effectuées à l’université d’Amsterdam. Il y eut 124 sessions et 46 succès, pour un taux de succès global de 37 %. Les taux de succès pour les quatre expériences furent individuellement de 34,3 %, de 37.5 %, de 40 % et de 36,1 %, les résultats sont donc homogènes au sein de ces quatre expériences.
Morris, Dalton, Delanoy et Watt (1995) ont publié les résultats de 97 sessions conduites à l’université d’Edimbourg, durant lesquelles il y eut 32 succès, pour un taux de succès de 33 %. Ils ont mené un nombre à peu près égal de sessions selon trois conditions. Dans l’une des conditions, il y avait un agentDans les cas spontanés, la personne vivant lévénement dont le récepteur va recevoir linformation ; dans les expérimentations de télépathie, lémetteur ; dans la psychokinèse :le sujet, considéré comme source du psi. connu, et dans les deux autres conditions, il a été aléatoirement défini à la dernière minute, et sans que le percipientPersonne qui perçoit les pensées et les images transmises par télépathie. On utilise aussi parfois l'expression d'émetteur. ne sache s’il y aurait ou non un agentDans les cas spontanés, la personne vivant lévénement dont le récepteur va recevoir linformation ; dans les expérimentations de télépathie, lémetteur ; dans la psychokinèse :le sujet, considéré comme source du psi.. Les taux de succès furent de 34 % quand il y avait un agentDans les cas spontanés, la personne vivant lévénement dont le récepteur va recevoir linformation ; dans les expérimentations de télépathie, lémetteur ; dans la psychokinèse :le sujet, considéré comme source du psi. connu et quand il n’y avait aucun agentDans les cas spontanés, la personne vivant lévénement dont le récepteur va recevoir linformation ; dans les expérimentations de télépathie, lémetteur ; dans la psychokinèse :le sujet, considéré comme source du psi., et de 28 % quand il y avait un agentDans les cas spontanés, la personne vivant lévénement dont le récepteur va recevoir linformation ; dans les expérimentations de télépathie, lémetteur ; dans la psychokinèse :le sujet, considéré comme source du psi. mais que le récepteurPôle réceptif dans un échange télépathique ; celui qui reçoit l’information ; opposé à émetteur ou agent. More ne savait pas si il y en avait un ou non. Les chercheurs ont découvert à postériori qu’un expérimentateur obtenait de meilleurs résultats que les deux autres.
Broughton et Alexander (1995) ont publié les résultats de 100 sessions effectuées à l’institut de ParapsychologieEtude rationnelle et pluridisciplinaire des faits semblant inexplicables dans l'état actuel de nos connaissances, et mettant en jeu directement le psychisme et son interaction avec l'environnement. C'est en 1889 que l'Allemand Max DESSOIR proposa les termes de parapsychologie pour "caractériser toute une région frontière encore inconnue qui sépare les états psychologiques habituels des états pathologiques", et de paraphysique pour désigner des phénomènes objectifs qui paraissent échapper aux lois de la physique classique. On parle plus spécifiquement de parapsychologie expérimentale pour désigner la parapsychologie dans le cadre du laboratoire. More de Caroline du nord. Ils ont aussi trouvé un taux de succès similaire, avec 33 réussites sur 100 sessions, soit 33 % de succès.
Les résultats des premières recherches de ganzfeldLe Ganzfeld (terme allemand qui signifie "champ sensoriel uniforme") est un protocole dinduction détat hypnagogique pour les expériences de télépathie. Le Ganzfeld est le protocole le plus utilisé actuellement en parapsychologie expérimentale. Il a été tout d'abord développé par Charles Honorton dans les années 1970. et ces trois reproductions sont récapitulés dans le tableau 3, conjointement aux résultats de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More du SRI et du SAIC. Les tailles d’effet pour les reproductions de GanzfeldLe Ganzfeld (terme allemand qui signifie "champ sensoriel uniforme") est un protocole dinduction détat hypnagogique pour les expériences de télépathie. Le Ganzfeld est le protocole le plus utilisé actuellement en parapsychologie expérimentale. Il a été tout d'abord développé par Charles Honorton dans les années 1970. sont basées sur le h de Cohen (Cohen’s h), qui est de nature similaire à la taille d’effet utilisée pour les données de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More. Les deux tailles d’effet mesurent le nombre d’écarts type au dessus du hasard atteints par les résultats, en utilisant l’écart type pour une session unique.
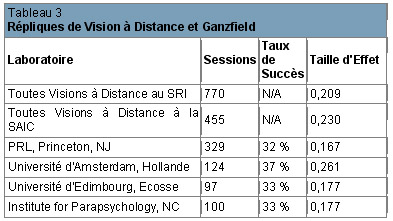
5.3 Conclusions concernant les reproductions d’expériences externes
Les résultats présentés dans le tableau 3 démontrent que les résultats des expériences de vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More ont été reproduits par un certain nombre de laboratoires et par différents expérimentateurs. Il s’agit donc d’un effet récurrent qui, s’il ne se présentait pas dans un domaine si peu commun, ne serait plus mis en doute par la science en tant que phénomène existant. Il est peu probable que des problèmes méthodologiques puissent expliquer l’uniformité remarquable des résultats présentés dans le tableau 3.
Même si nous convenons que la connaissance anormale est possible, reste à savoir si elle pourrait avoir une quelconque utilité pour le gouvernement. La réponse à cette question dépasse le cadre de ce rapport, mais quelques propositions peuvent être faites sur la façon d’accroître son utilité.
Premièrement, il s’avère que la connaissance anormale est répartie au sein de la population. Aucune des expériences de GanzfeldLe Ganzfeld (terme allemand qui signifie "champ sensoriel uniforme") est un protocole dinduction détat hypnagogique pour les expériences de télépathie. Le Ganzfeld est le protocole le plus utilisé actuellement en parapsychologie expérimentale. Il a été tout d'abord développé par Charles Honorton dans les années 1970. n’a utilisé exclusivement des sujets sélectionnés. Cependant, certains sujets sont plus talentueux que d’autres, et il est plus facile de trouver ces individus que d’en former d’autres. Il semble également que certains individus soient meilleurs pour certaines tâches que pour d’autres. Par exemple, le voyant 372 du SAIC semble avoir une facilité à décrire les sites techniques.
En second lieu, si la vision à distancePerception extra sensorielle d’un lieu situé à distance du récepteur. More doit se révéler utile, ceux qui l’utilisent doivent être formés à ce qu’elle peut permettre de faire et de ne pas faire. Compte tenu de notre niveau de compréhension actuel, elle est rarement précise à 100 %, et il n’y a aucun moyen fiable de distinguer a priori les informations pertinentes de celles qui ne le sont pas. Il en va probablement de même pour la plupart des sources de renseignement.
Troisièmement, ce qui peut s’avérer utile pour un objectif, peut ne pas l’être pour un autre. Par exemple, supposons qu’un sujet psiIndividu qui semble produire des phénomènes psi de façon particulièrement intense ou fiable. puisse décrire le lieu dans lequel un otage est détenu. Cette information pourrait ne pas être utile à ceux qui ne connaissent pas les lieux, mais se révéler l’être pour ceux qui le connaissent suffisamment.
Il est clair, pour l’auteur, que la connaissance anormale est possible et que son existence a été démontrée. Cette conclusion n’est pas fondée sur la croyance, mais sur des critères scientifiques communément admis. Ce phénomène a été reproduit dans des laboratoires différents. Les expériences au cours desquelles la connaissance anormale a été observée sont suffisamment indépendantes. De plus, s’il y avait une explication différente pour chacune de ces expériences, c’est à dire des biaisPrésence de patterns ou de défauts particuliers pouvant introduire une modification arbitraire des résultats et faussant ainsi leur validité (ex : un dé non équilibré ayant tendance à faire sortir souvent le même chiffre). méthodologiques subtils, leur impact ne devrait pas être identique pour l’ensemble des expériences et des laboratoires. De la même façon, si la fraude était en cause, elle impliquerait une fraude de grande ampleur de la part d’un grand nombre d’expérimentateurs ou d’un nombre encore plus grand de sujets.
Il n’est en revanche pas aussi évident que nous ayons beaucoup progressé dans la compréhension des processus psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi.. Les agents ne semblent pas être nécessaires ; communiquer la réponse correcte (feedback1. rétroaction de linformation dans les systèmes cybernétiques ; information renvoyée au sujet sur nimporte quelle mesure prise sur lui-même (physiologique, psychologique, tests psi) ; 2. moyen utilisé pour lui redonner cette information (ex : feedback auditif, feedback visuel, etc.).) peut ou non être utile. La distance, dans le temps et l’espace, ne semble pas être une limite à ces perceptions. Au delà de ces quelques conclusions, nous ne savons que peu de choses sur le connaissance anormale.
Je pense fortement que continuer à rechercher des preuves de l’existence du psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi. serait une dépense d’argent inutile. Toute personne qui examine les données obtenues en laboratoire, prises dans leur ensemble, ne peut mettre en évidence des problèmes méthodologiques, ou statistiques, susceptible d’expliquer les résultats obtenus jusqu’à aujourd’hui, et qui continuent à s’accumuler tout en restant cohérents. Des fonds devraient être attribués pour comprendre la façon dont ces facultés fonctionnent. Ces interrogations ne sont pas plus inaccessibles que toute autre recherche scientifique mettant en cause des phénomènes ayant des tailles d’effets petites et moyennes. Si des ressources financières suffisantes sont attribuées pour l’étude de ces questions, nous pourrons certainement obtenir des réponses à leur sujet durant la prochaine décennie.
Bem, Daryl J. and Charles HonortonCharles Honorton s'est intéressé très tôt à la parapsychologie. Adolescent, il échangea avec Joseph Rhine, et étudiant, il passa ses mois d'été au Laboratoire de Parapsychologie d’université de Duke en Caroline du Nord. Charles Honorton collabora avec Stanley Krippner et Montague Ullman au Maimonides Medical Center (Brooklyn, New York) lors des expériences de Rêve télépathique. Devenu directeur de la division de parapsychologie au Maimonides, il fonda en 1979 le Psychophysical Research Laboratories (PRL) à Princeton dans le New Jersey. Il est décédé en 1992 laissant derrière lui un nombre important de publications de parapsychologie, sa principale contribution en parapsychologie étant le développement du protocole Ganzfeld. More (1994). « Does psiThouless et Wiesner ont introduit en 1942 lexpression "Phénomène psi" (et non "psy"), de la lettre grecque Psi, qui se voulait un terme neutre simplement destiné à désigner le "facteur inconnu" dans les expériences de parapsychologie, en opposition avec les communications sensori-motrices habituelles. On utilise ainsi le terme psi comme signifiant de façon générale une communication anormale avec lenvironnement (perceptions extra-sensorielles ou psychokinèse). On utilise fréquemment en parapsychologie les expressions de sujet psi, de perceptions psi et de phénomènes psi. exist? Replicable evidence for an anomalous process of information transfer, » Psychological Bulletin, 115, 4-18.
Bierman, Dick J. (1995). « The Amsterdam GanzfeldLe Ganzfeld (terme allemand qui signifie "champ sensoriel uniforme") est un protocole dinduction détat hypnagogique pour les expériences de télépathie. Le Ganzfeld est le protocole le plus utilisé actuellement en parapsychologie expérimentale. Il a été tout d'abord développé par Charles Honorton dans les années 1970. Series III & IV: Target clip emotionality, effect sizes and openness, » Proceedings of the 38th Annual Parapsychological AssociationLa Parapsychological Association (PA) est une organisation internationale constituée de scientifiques et d'universitaires qui étudient les phénomènes psi, comme la télépathie, la clairvoyance, la psychokinèse, la guérison psychique ou la précognition. La Parapsychological Association est reconnue comme une association scientifique à part entière, étant membre de l'AAAS depuis 1969. C'est le plus important organisme de recherche en parapsychologie. La plupart des parapsychologues sont membre de PA. elle permet de féderer l'ensemble des chercheurs travaillant dans le domaine de la parapsychologie et organise chaque année un congrès où sont publiées les recherches scientifiques des parapsychologues. Elle a pour objectif de promouvoir l'approche scientifique et objective des phénomènes psi et ses membres obeissent à une charte de déontologie. Convention, 27-37.
Broughton, Richard and Cheryl Alexander (1995). « Autoganzfeld II: The first 100 sessions, » Proceedings of the 38th Annual Parapsychological AssociationLa Parapsychological Association (PA) est une organisation internationale constituée de scientifiques et d'universitaires qui étudient les phénomènes psi, comme la télépathie, la clairvoyance, la psychokinèse, la guérison psychique ou la précognition. La Parapsychological Association est reconnue comme une association scientifique à part entière, étant membre de l'AAAS depuis 1969. C'est le plus important organisme de recherche en parapsychologie. La plupart des parapsychologues sont membre de PA. elle permet de féderer l'ensemble des chercheurs travaillant dans le domaine de la parapsychologie et organise chaque année un congrès où sont publiées les recherches scientifiques des parapsychologues. Elle a pour objectif de promouvoir l'approche scientifique et objective des phénomènes psi et ses membres obeissent à une charte de déontologie. Convention, 53-61.
May, Edwin C. (1995). « AC Technical trials: Inspiration for the target entropy concept, » May 26, 1995, SAIC Technical Report.
May, Edwin C., Nevin D. Lantz and Tom Piantineda (1994). « Feedback1. rétroaction de linformation dans les systèmes cybernétiques ; information renvoyée au sujet sur nimporte quelle mesure prise sur lui-même (physiologique, psychologique, tests psi) ; 2. moyen utilisé pour lui redonner cette information (ex : feedback auditif, feedback visuel, etc.). Considerations in Anomalous Cognition Experiments, » Technical Report, 29 November 1994.
May, Edwin C., J.M. Utts, V.V. Trask, W.W. Luke, T.J. Frivold and B.S. Humphrey (1988). « Review of the psychoenergetic research conducted at SRI International (1973-1988) » SRI International Technical Report, March 1989.
Morris, Robert L., Kathy Dalton, Deborah Delanoy and Caroline Watt (1995). « Comparison of the sender/no sender condition in the GanzfeldLe Ganzfeld (terme allemand qui signifie "champ sensoriel uniforme") est un protocole dinduction détat hypnagogique pour les expériences de télépathie. Le Ganzfeld est le protocole le plus utilisé actuellement en parapsychologie expérimentale. Il a été tout d'abord développé par Charles Honorton dans les années 1970., » Proceedings of the 38th Annual Parapsychological AssociationLa Parapsychological Association (PA) est une organisation internationale constituée de scientifiques et d'universitaires qui étudient les phénomènes psi, comme la télépathie, la clairvoyance, la psychokinèse, la guérison psychique ou la précognition. La Parapsychological Association est reconnue comme une association scientifique à part entière, étant membre de l'AAAS depuis 1969. C'est le plus important organisme de recherche en parapsychologie. La plupart des parapsychologues sont membre de PA. elle permet de féderer l'ensemble des chercheurs travaillant dans le domaine de la parapsychologie et organise chaque année un congrès où sont publiées les recherches scientifiques des parapsychologues. Elle a pour objectif de promouvoir l'approche scientifique et objective des phénomènes psi et ses membres obeissent à une charte de déontologie. Convention, 244-259.
Puthoff, Harold E. and Russell Targ (1975). « Perceptual Augmentation Techniques: Part Two–Research Report, » Stanford Research Institute Final Report, Dec. 1, 1975.
Les annexes du rapport sont en cours de traduction.
APPENDIX 1
EFFECT SIZE MEASURE USED WITH RANK ORDER JUDGING
In general, effect sizes measure the number of standard deviations the true population value of interest falls from the value that would be true if chance alone were at work. The standard deviation used is for one subject, trial, etc., rather than being the standard error of the sample statistic used in the hypothesis test.
In rank-order judging, let R be the rank for one trial. If the number of possible choices is N, then we find:
E(R) = (N + 1)/2
and
Var(R) = (N-squared – 1)/12.
Therefore, when N = 5, we find E(Ri) = 3 and Var(Ri) = 2. The effect size is therefore:
Effect Size = (3.0 – Average Rank)/sqrt(2).
APPENDIX 2
A BRIEF DESCRIPTION OF THE SAIC EXPERIMENTS
Experiments Involving Remote ViewingLe Remote Viewing (vision à distance) est une technique utilisée lors de protocoles de parapsychologie en vu d'étudier les perceptions extra-sensorielles. Les techniques de vision à distance ont pour origine les travaux de René Warcollier. Elle ont ensuite été développées au sein du programme de vision à distance commandité par la CIA dans les années 1970. Jusqu'en 1995, les chercheurs qui ont participé à ce programme se sont efforcés d'utiliser les techniques de remote viewing afin de tenter de développer des applications du psi, en particulier dans le domaine du renseignement.
There were six experiments involving remote viewingLe Remote Viewing (vision à distance) est une technique utilisée lors de protocoles de parapsychologie en vu d'étudier les perceptions extra-sensorielles. Les techniques de vision à distance ont pour origine les travaux de René Warcollier. Elle ont ensuite été développées au sein du programme de vision à distance commandité par la CIA dans les années 1970. Jusqu'en 1995, les chercheurs qui ont participé à ce programme se sont efforcés d'utiliser les techniques de remote viewing afin de tenter de développer des applications du psi, en particulier dans le domaine du renseignement., done for a variety of purposes.
Experiment 1: Target and Sender Dependencies:
Purpose: This experiment was designed to test whether or not a sender is necessary for successful remote viewingLe Remote Viewing (vision à distance) est une technique utilisée lors de protocoles de parapsychologie en vu d'étudier les perceptions extra-sensorielles. Les techniques de vision à distance ont pour origine les travaux de René Warcollier. Elle ont ensuite été développées au sein du programme de vision à distance commandité par la CIA dans les années 1970. Jusqu'en 1995, les chercheurs qui ont participé à ce programme se sont efforcés d'utiliser les techniques de remote viewing afin de tenter de développer des applications du psi, en particulier dans le domaine du renseignement. and whether or not dynamic targets, consisting of short video clips, would result in more successful remote viewingLe Remote Viewing (vision à distance) est une technique utilisée lors de protocoles de parapsychologie en vu d'étudier les perceptions extra-sensorielles. Les techniques de vision à distance ont pour origine les travaux de René Warcollier. Elle ont ensuite été développées au sein du programme de vision à distance commandité par la CIA dans les années 1970. Jusqu'en 1995, les chercheurs qui ont participé à ce programme se sont efforcés d'utiliser les techniques de remote viewing afin de tenter de développer des applications du psi, en particulier dans le domaine du renseignement. than the standard National Geographic photographs used in most of the SRI experiments.
Method: Five experienced remote viewers participated, three of whom (#s 009, 131 and 372) were included in the experienced group at SRI; their identification numbers were carried over to the SAIC experiments. Each viewer worked from his or her home and faxed the results of the sessions to the principal investigator, Nevin Lantz, located in Pennsylvania. Whether the target was static or dynamic and whether or not there was a sender was randomly determined and unknown to the viewer. Upon receiving the fax of the response, Dr. Lantz mailed the correct answer to the viewer. The original response was sent to SAIC in California, where the results were judged by an analyst blind to the correct target. Standard rank-order judging was used.
Since it is not explicitly stated, I asked Dr. May what measures were taken to make sure the viewer actually mailed the original response to SAIC before receiving the correct answer in the mail. He said that the original faxed responses were compared with the responses received by SAIC to make sure they were the same, and they all were.
Results: Each viewer contributed ten trials under each of the four possible conditions (sender/no sender and static/dynamic target), for a total of 40 trials per viewer. There was a moderate difference (effect size = .121, p = .08) between the static and dynamic targets, with the traditional National Geographic photographs faring better than the dynamic video clips. There was no noticeable difference based on whether or not a sender was involved, supporting the same conclusion reached in the overall analysis of the SRI work. Combined over all conditions and all viewers, the effect size was 0.124 (p = .04); for the static targets alone it was .248 (exact p = .0073) while for the dynamic targets it was 0.00 (p = .50).
Discussion: The SAIC staff speculated that the dynamic targets were not successful because the possibilities were too broad. They chose a new set of dynamic targets to be more similar to the static targets and performed another experiment the following year to compare the static targets with the more similar set of dynamic ones. That experiment is described below (Experiment 10.)
Experiment 4: Enhancing Detection of AC with Binary Coding:
Purpose: This experiment was designed to see if remote viewingLe Remote Viewing (vision à distance) est une technique utilisée lors de protocoles de parapsychologie en vu d'étudier les perceptions extra-sensorielles. Les techniques de vision à distance ont pour origine les travaux de René Warcollier. Elle ont ensuite été développées au sein du programme de vision à distance commandité par la CIA dans les années 1970. Jusqu'en 1995, les chercheurs qui ont participé à ce programme se sont efforcés d'utiliser les techniques de remote viewing afin de tenter de développer des applications du psi, en particulier dans le domaine du renseignement. could be used to develop a message-sending capability by focusing on the presence or absence of five specific features of a target. The target set was constructed in packets of four, with possible combinations of the absence (0) or presence (1) of each of the five features chosen to correspond to the numbers 00000, 01110, 10101, and 11011. This is standard practice in information theory when trying to send a two digit number (00, 01, 10 or 11); the remaining three bits are used for « error correction. » Different sets of five features were used for each of ten target packs.
Method: Five viewers each contributed eight trials, but the same eight targets were used for all five viewers. There was no sender used, and viewers were told that each target would be in a fixed location for one week. They were to spend 15 minutes trying to draw the target, then fax their responses to SAIC in California. The results were blind-judged and the binary features were coded by both the viewers and an independent analyst.
Results: The results were unsuccessful in showing any evidence of psychic functioning. Neither standard rank-order judging nor analysis based on the binary guesses showed any promise that this method works to send messages.
Experiment 5: AC in Lucid Dreams (Baseline):
Purpose: Despite its name, this experiment did not involve lucid dreaming. Instead, it was used to test three novice remote viewers who were to participate in an experiment involving remote viewingLe Remote Viewing (vision à distance) est une technique utilisée lors de protocoles de parapsychologie en vu d'étudier les perceptions extra-sensorielles. Les techniques de vision à distance ont pour origine les travaux de René Warcollier. Elle ont ensuite été développées au sein du programme de vision à distance commandité par la CIA dans les années 1970. Jusqu'en 1995, les chercheurs qui ont participé à ce programme se sont efforcés d'utiliser les techniques de remote viewing afin de tenter de développer des applications du psi, en particulier dans le domaine du renseignement. while dreaming. This baseline experiment was designed to see if these individuals would be successful at standard laboratory remote viewingLe Remote Viewing (vision à distance) est une technique utilisée lors de protocoles de parapsychologie en vu d'étudier les perceptions extra-sensorielles. Les techniques de vision à distance ont pour origine les travaux de René Warcollier. Elle ont ensuite été développées au sein du programme de vision à distance commandité par la CIA dans les années 1970. Jusqu'en 1995, les chercheurs qui ont participé à ce programme se sont efforcés d'utiliser les techniques de remote viewing afin de tenter de développer des applications du psi, en particulier dans le domaine du renseignement..
Method: For this baseline experiment, each of the three viewers contributed eight trials using a standard protocol common in the SRI era. For each trial, a target was randomly chosen from the set of 100 National Geographic targets used at SRI and SAIC. The target was placed on a table (so no sender was used) while the viewer, in another room, was asked to provide a description. The response was later blind-judged by comparing it to the target and four decoys, and providing a rank-ordering of the five choices.
Results: Of the three novice viewers, one obtained a promising effect size of .265, although the result was not statistically significant due to the small number of trials (8). Individual results were not provided for the other two viewers, but the overall effect size was reported as 0.088 for the three viewers.
Experiment 6: AC in Lucid Dreams (Pilot):
Purpose: A lucid dream is a dream in which one becomes aware that he or she is dreaming, and can control subsequent events in the dream. This ability has apparently been successfully trained by Dr. Stephen LaBerge of the Lucidity Institute. He was the Principal Investigator for this experiment. The experiment was designed to see if remote viewingLe Remote Viewing (vision à distance) est une technique utilisée lors de protocoles de parapsychologie en vu d'étudier les perceptions extra-sensorielles. Les techniques de vision à distance ont pour origine les travaux de René Warcollier. Elle ont ensuite été développées au sein du programme de vision à distance commandité par la CIA dans les années 1970. Jusqu'en 1995, les chercheurs qui ont participé à ce programme se sont efforcés d'utiliser les techniques de remote viewing afin de tenter de développer des applications du psi, en particulier dans le domaine du renseignement. could be successfully employed while the viewer was having a lucid dream.
Method: Seven remote viewers were used; four were experienced SAIC remote viewers and three were experienced lucid dreamers from the Lucidity Institute. The latter three were the novice viewers used in Experiment 5. The experienced SAIC remote viewers were given training in lucid dreaming. The number of trials contributed by each viewer could not be fixed in advance because of the difficulty of attaining the lucid dream state. A total of 21 trials were conducted, with the seven viewers contributing anywhere from one to seven trials each. The report did not mention whether or not the stopping criterion was fixed in advance, but according to Dr. May the experiment was designed to proceed for a fixed time period and to include all sessions attained during that time period.
Unlike with standard well-controlled protocols, the viewers were allowed to take the target material home with them. The targets, selected from the standard National Geographic pool, were sealed in opaque envelopes with covert threads to detect possible tampering (there were no indications of such tampering). Viewers were instructed to place the targets at bedside and to attempt a lucid dream in which the envelope was opened and the target viewed. Drawings and descriptions were then to be produced upon awakening.
Results: The results were blind-judged using the standard sum of ranks. Since the majority of viewers contributed only one or two trials, analysis by individual viewer would be meaningless. For the 21 trials combined, the effect size was 0.368 (p = .046). Information was not provided to differentiate the novice remote viewers from the experienced ones.
Experiment 9: ERD AC Behavior:
Purpose: The remote viewingLe Remote Viewing (vision à distance) est une technique utilisée lors de protocoles de parapsychologie en vu d'étudier les perceptions extra-sensorielles. Les techniques de vision à distance ont pour origine les travaux de René Warcollier. Elle ont ensuite été développées au sein du programme de vision à distance commandité par la CIA dans les années 1970. Jusqu'en 1995, les chercheurs qui ont participé à ce programme se sont efforcés d'utiliser les techniques de remote viewing afin de tenter de développer des applications du psi, en particulier dans le domaine du renseignement. in this experiment was conducted in conjunction with measurement of brain waves using an EEG. The purpose of the experiment was to see whether or not EEG activity would change when the target the person was attempting to describe was briefly displayed on a computer monitor in a distant room. Details of the EEG portion will be explained as experiment 8. Here, we summarize the remote viewingLe Remote Viewing (vision à distance) est une technique utilisée lors de protocoles de parapsychologie en vu d'étudier les perceptions extra-sensorielles. Les techniques de vision à distance ont pour origine les travaux de René Warcollier. Elle ont ensuite été développées au sein du programme de vision à distance commandité par la CIA dans les années 1970. Jusqu'en 1995, les chercheurs qui ont participé à ce programme se sont efforcés d'utiliser les techniques de remote viewing afin de tenter de développer des applications du psi, en particulier dans le domaine du renseignement. part of the study.
Method: Three experienced remote viewers (#s 009, 372 and 389) participated. Because of the pilot nature of the experiment, the number of trials differed for each viewer based on availability, with viewers 009, 372 and 389 contributing 18, 24 and 28 trials, respectively. Although it is not good protocol to allow an unspecified number of trials, it does not appear that this problem can explain the results of this experiment.
Results: Responses were blind-judged using standard rank-order analysis. The effect sizes for the viewers 009, 372 and 389 were 0.432 (p = .033), 0.354 (p = .042) and 0.177 (p = .175), respectively. The overall effect size was 0.303 (p = 0.006).
Experiment 10: Entropy II:
Purpose: This experiment was designed as an improved version of Experiment 1. After the unsuccessful showing for the dynamic targets in Experiment 1, the SAIC team speculated that the « target pool bandwidth » defined as the number of « cognitively differentiable elements » in the target pool might be an important factor. If the possible target material was extremely broad, viewers might have trouble filtering out extraneous noise. If the set of possibilities was too small, as in forced choice experiments, the viewer would see all choices at once and would have trouble filtering out that knowledge. An intermediate range of possibilities, too large to be considered all at once, was predicted to be ideal. The standard National Geographic pool seemed to fit that range. For this experiment, a pool of dynamic targets was created with a similar « band-width. » In both Experiments (1 and 10) the researchers predicted that remote viewingLe Remote Viewing (vision à distance) est une technique utilisée lors de protocoles de parapsychologie en vu d'étudier les perceptions extra-sensorielles. Les techniques de vision à distance ont pour origine les travaux de René Warcollier. Elle ont ensuite été développées au sein du programme de vision à distance commandité par la CIA dans les années 1970. Jusqu'en 1995, les chercheurs qui ont participé à ce programme se sont efforcés d'utiliser les techniques de remote viewing afin de tenter de développer des applications du psi, en particulier dans le domaine du renseignement. success would correlate with the change in visual entropy of the target, as explained in Section 4.6.1.
Method: Four of the five viewers from Experiment 1 were used (#s 009, 372, 389 and 518). They each contributed equal numbers of sessions with static and dynamic targets, with the viewers blind to which trials had which type. Senders were not used, and all sessions were conducted at SAIC in California, unlike Experiment 1 in which the viewers worked at home. Viewer #372 contributed 15 of each type while the others each contributed 10 of each type. Standard rank-order judging was used.
Results: Table 4 shows the results for this experiment. Unlike in Experiment 1, the static and dynamic targets produced identical effect sizes, with both types producing very successful results. The combined effect size for all trials is .55, resulting in a z-score of 5.22.
(Pour voir le tableau 4, se réferer à la publication originale)
The Other Experiments at SAIC
There were four additional experiments at SAIC, not involving remote viewingLe Remote Viewing (vision à distance) est une technique utilisée lors de protocoles de parapsychologie en vu d'étudier les perceptions extra-sensorielles. Les techniques de vision à distance ont pour origine les travaux de René Warcollier. Elle ont ensuite été développées au sein du programme de vision à distance commandité par la CIA dans les années 1970. Jusqu'en 1995, les chercheurs qui ont participé à ce programme se sont efforcés d'utiliser les techniques de remote viewing afin de tenter de développer des applications du psi, en particulier dans le domaine du renseignement.. Two of them (experiments 3 and 8) involved trying to measure brain activity related to psychic functioning and will be described briefly. Experiment 3 used a magnetoenchephalograph (MEG) to attempt to detect anomalous signals in the brain when a remote stimulus was present. Due to the background noise in the brain measurements and the expected strength of the signal, the experimenters realized too late that they would not be able to detect a signal even if it existed. Experiment 8 utilized an EEG to try to detect the interruption of alpha waves when a remote viewingLe Remote Viewing (vision à distance) est une technique utilisée lors de protocoles de parapsychologie en vu d'étudier les perceptions extra-sensorielles. Les techniques de vision à distance ont pour origine les travaux de René Warcollier. Elle ont ensuite été développées au sein du programme de vision à distance commandité par la CIA dans les années 1970. Jusqu'en 1995, les chercheurs qui ont participé à ce programme se sont efforcés d'utiliser les techniques de remote viewing afin de tenter de développer des applications du psi, en particulier dans le domaine du renseignement. target was briefly displayed on a computer monitor in another room. The area of the brain tested was that corresponding to visual stimuli. No significant change in alpha was seen.
The remaining two experiments were replications of previous work measuring psychic functioning in areas other than remote viewingLe Remote Viewing (vision à distance) est une technique utilisée lors de protocoles de parapsychologie en vu d'étudier les perceptions extra-sensorielles. Les techniques de vision à distance ont pour origine les travaux de René Warcollier. Elle ont ensuite été développées au sein du programme de vision à distance commandité par la CIA dans les années 1970. Jusqu'en 1995, les chercheurs qui ont participé à ce programme se sont efforcés d'utiliser les techniques de remote viewing afin de tenter de développer des applications du psi, en particulier dans le domaine du renseignement.. They will be described in detail.
Experiment 2: AC of Binary Targets:
Purpose: This experiment attempted to replicate and enhance random number generator experiments conducted at SRI. In these types of experiments a computer randomly selects one of two choices to be the target, denoted as 0 or 1. The internal workings of the computer then rapidly oscillate between 0 and 1 and the subject pushes a mouse button when he or she thinks the internal choice matches the target choice. This process is repeated over many trials. The computer tabulates the results and the experiment is a success if the subject guesses the correct answer more often than would be expected by chance. The purpose is to see if humans can correctly guess computer-selected binary targets, and hopefully by extension, correctly solve binary choice problems in real situations. If that were to be the case, then real problems could be posed as binary ones (e.g. is the lost child still in this city or not) to narrow down possibilities.
Method: This SAIC experiment was designed to enhance the accuracy of binary guessing by using a statistical technique called sequential analysis. Rather than just one guess for each decision, the subject continues to guess until the computer ascertains that a decision has been reached. The computer keeps track of the number of times zero and one have each been guessed and announces a decision when one of the choices has clearly won out over the other, or when it is clear that it is essentially an ongoing tie. In the latter case, no decision is recorded. Three subjects participated (#s 007, 083 and 531) in this experiment. Subject #531 had been successful in similar experiments at SRI.
Results: Using this method for enhancing the accuracy of the guesses, subject #531, who had been successful in previous similar experiments, was able to achieve 76 correct answers out of 100 tries. This remarkable level of scoring for this type of experiment resulted in an effect size of .520 and a z-score of 5.20. The other two subjects did not differ from chance results, with 44 and 49 correct decisions out of 100 or 101. (One subject accidentally contributed an additional trial.)
Although the result for subject 531 is remarkably successful, it does not represent a very efficient method of obtaining the decision. To reach the 100 decisions required a total of 21,337 guesses, i.e. over 200 guesses for each decision. Of the individual guesses, only 51.6 percent were correct, for an effect size of .032, similar to other forced choice experiments. Due to the large number of guesses, the corresponding z -score was 4.65. Combined over all three subjects, 56 percent of the 301 decisions were correct and the effect size was 0.123. The combined results were still statistically significant, with p = 0.017, as shown in Table 1.
Experiment 7: Remote Observation:
Purpose: It is often reported anecdotally that people know when they are being watched. Two experiments were conducted at SAIC to determine whether or not these anecdotes could be supported by a change in physiology when someone is being observed from a distance. The experimental design was essentially the same for the two experiments. This work was a conceptual replication of results reported by researchers in the Former Soviet Union (FSU), the United States and Scotland. The experiments in the FSU were interpreted to mean that the physiology of the recipient was being manipulated by the sender, an effect that if real could have frightening consequences.
Method: The « observee » was seated in a room with a video camera focused on him or her, and with galvanic skin response measurements being recorded. In a distant room the « observer » attempted to influence the physiology of the observee at randomly spaced time intervals. During those time intervals, an image of the observee appeared on a computer monitor watched by the observer. During « control » periods, the video camera remained focused on the observee but the computer monitor did not display his or her image to the observer. There were 16 « influence » periods randomly interspersed with 16 « control » periods, each of 30 seconds, with blank periods of 0 to 5 seconds inserted to rule out patterns in physiology.
Results: To determine whether or not the galvanic skin response of the observees was activated while they were being watched, the response during the control periods was compared with the response during the « influence » periods for each subject. The results were then averaged across subjects. In both experiments, there was greater activity during the periods of being watched than there was during the control periods. The results were statistically significant in each case (p = .036 and .014) and the effect sizes were similar, at 0.39 and 0.49. As preplanned, the results were combined, yielding an effect size of .39 (p = .005). As an interesting post hoc observation, it was noted that the effect was substantially stronger when the observer and observee were of opposite sexes than when they were of the same sex.
Discussion: This experiment differs from the others conducted at SAIC since it involves interaction between two people rather than one person ascertaining information about the environment or the future. It raises substantially more questions than it answers, since the mechanism for the shift in physiology is unknown. Possibilities range from the idea that the observee was able to know when the computer in the distant room was displaying his or her image, not unlike remote viewingLe Remote Viewing (vision à distance) est une technique utilisée lors de protocoles de parapsychologie en vu d'étudier les perceptions extra-sensorielles. Les techniques de vision à distance ont pour origine les travaux de René Warcollier. Elle ont ensuite été développées au sein du programme de vision à distance commandité par la CIA dans les années 1970. Jusqu'en 1995, les chercheurs qui ont participé à ce programme se sont efforcés d'utiliser les techniques de remote viewing afin de tenter de développer des applications du psi, en particulier dans le domaine du renseignement., to the possibility that the observer actually did influence the physiology of the observee. Further experimentation as well as a review of similar past experiments may be able to shed light on this important question.